Professor
Electrical Engineering
and Computer Science
University of Michigan


Jason J. Corso
| Email: | jjcorso@eecs.umich.edu |
| Office: | 4238 EECS |
| Phone: | 734-647-8833 |
| Bio: | [txt] |
| Vita: | [pdf] |
| Hours: |
Thursday 1030-1200
If urgent: eecs-corso-va@umich.edu |
| Cal: | Availability |
| Email Policy | |
Index Page Anchors
Publication Tag Cloud
VQA action detection action prediction action segmentation active clustering activity recognition artificial intelligence attribute augmented reality autonomous driving belief propagation bioinformatics biomarkers biometrics braintumor cognitive systems computational finance computer forensics computer graphics computer vision computer-aided diagnosis control cosegmentation data mining deep learning deep reinforcement learning deformable dictionary transfer digitial humanities document imaging domain adaptation dynamic linear models endoscopy evaluation event recognition facade detection face detection face recognition feature extraction frame interpolation fusion gesture recognition gpu grammar graph cuts graph-based graphical models haptics hierarchical higher-order human pose estimation human-computer interaction human-in-the-loop hybrid intelligence image captioning image denoising image processing image retrieval image understanding inference information fusion inpainting language grounding localization lung imaging machine learning mapping max-margin medical imaging metric learning mobile manipulation mobile robotics mosaicking motion estimation mrf multimedia natural language navigation neuroimaging object detection object grounding object-object interaction ontology particle filters pretraining probabilistic ontology protein structure prediction random forest reconstruction robotics segmentation semantic segmentation semi-supervised single-view depth estimation sketch generation slam spectral clustering spine imaging stereo streaming supervoxel surgical robotics tomographic reconstruction tracking video inpainting video object segmentation video prediction video saliency video segmentation video summarization video to text video understanding viewpoint estimation vision and language vision-based control visual psychophysics visual servo control volume rendering voxel maps weak supervision
Dr. Jason J. Corso is currently the Toyota Professor of AI and a Professor of Electrical
Engineering and Computer Science at the University of Michigan. He received
his Ph.D. in Computer Science at The Johns Hopkins University in 2005. He is a
recipient of the NSF CAREER award (2009), ARO Young Investigator award (2010), Google Faculty Research Award (2015) and on the DARPA CSSG.
He is also the Co-Founder and CEO of Voxel51, a computer vision tech startup that is building the state of the art platform for video and image based applications.
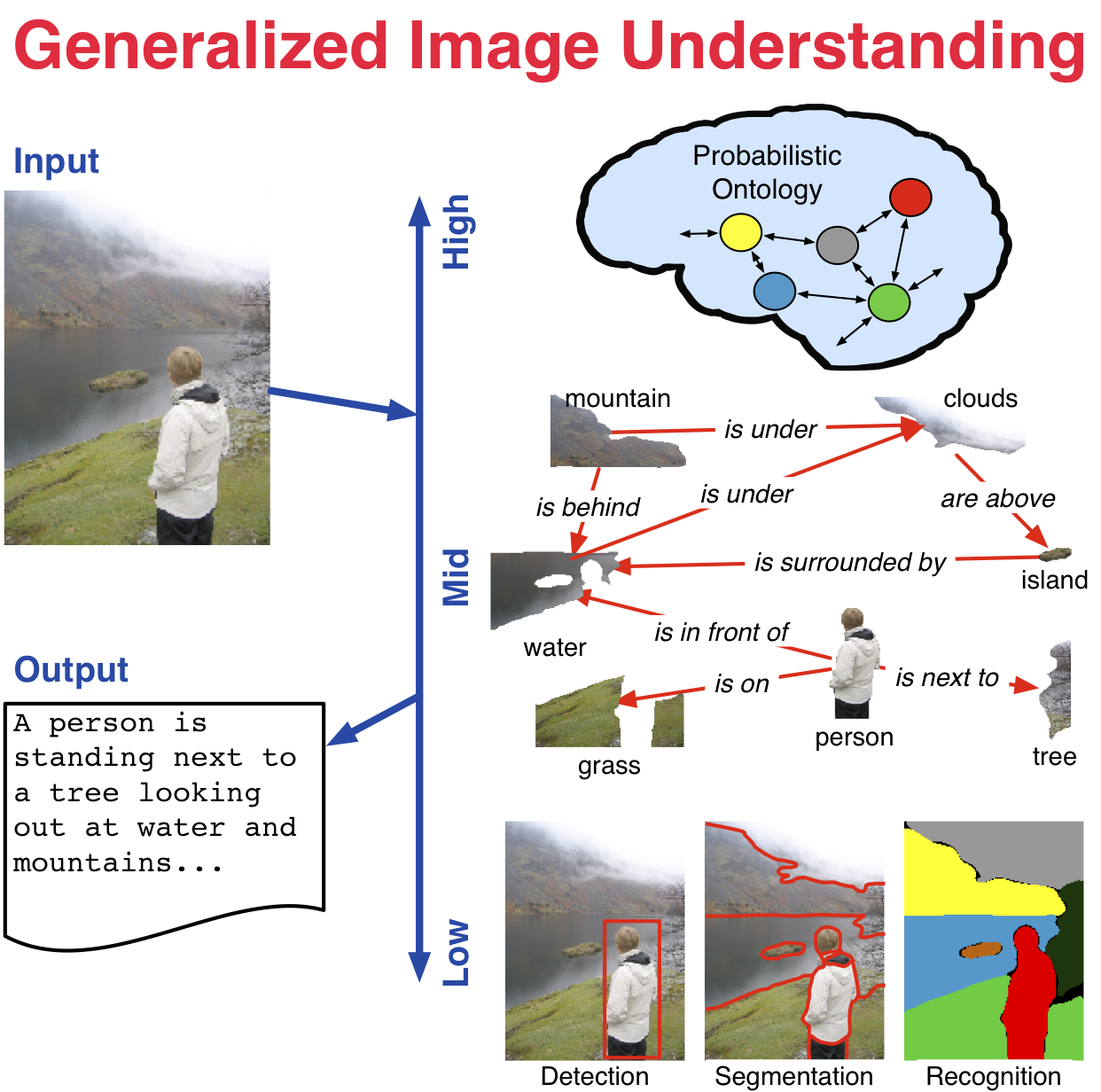
His main research thrust is high-level computer vision and its
relationship to human language, robotics and data science. He
primarily focuses on problems in video understanding such as video
segmentation, activity recognition, and video-to-text. From
biomedicine to recreational video, imaging data is ubiquitous. Yet,
imaging scientists and intelligence analysts are without an adequate
language and set of tools to fully tap the information-rich image and
video. He works to provide such a language; specifically, he
primarily studies the coupled problems of segmentation and recognition
from a Bayesian perspective emphasizing the role of statistical models
in efficient visual inference. His long-term goal is a comprehensive
and robust methodology of automatically mining, quantifying, and
generalizing information in large sets of projective and volumetric
images and video.
|
Selected Publications
[complete list here]
[google scholar]
Code and Data Downloads
publication-code is linked from papers in pubs
ViP is a PyTorch-based video software platform for problems like video object detection, activity recognition, event classification that makes working with video models much easier. See the Technical Report for more information.
ActivityNet-Entitiesadd grounded bounding boxes to the ActivityNet dataset for the purposes of grounded video description. This was released with our CVPR 2019 paper.
M-PACT is a general purpose software framework for video understanding, including activity recognition, video classification, and others; it is based on TensorFlow. This technical report describes it in more detail.
YouCook2
is the largest task-oriented, instructional video dataset in the vision community. It contains 2000 long untrimmed videos from 89 cooking recipes. The procedure steps for each video are annotated with temporal boundaries and described by imperative English sentences. ArXiV report for the paper/data.
Click-Here CNNs: This is the project page supplying code and data associated with our ICCV 2017 paper.
A2D: Actor-Action Dataset is a new
dataset to support a broad class of video understanding problems:
action recognition, actor-class recognition, multi-label
actor/action recognition, actor-action semantic segmentation.
Data and evaluation code is available. This dataset was released
with our CVPR
2015 paper.
Video2Text.net:
A website and web-service for automatic conversion of videos to natural
language sentences based on the video content. This website showcases our work
in the vision+language domain.
YouCook data set: 88 challenging
videos of various cooking (third-person viewpoint, different
backgrounds, dynamic camera and person movement) with natural
language annotations (about 8 per video) and object and action
annotations. Includes a benchmark ROUGE scoring evaluation. The
data set was published with our CVPR
2013 paper.
Hierarchy
Agreement Index: implementation of our AAAI LBP
2013 cross-hierarchy evaluation tool for general use.
Random Forest Distance -- tree-structured metric learning that implicitly adapts the metric over the sample space based on our KDD 2012 paper. (Code updated 2/28/14)
Action Bank full code and processed data sets [direct link to code]
LIBSVX: A Supervoxel Library and Benchmark for Early Video Processing. Implements a suite of supervoxel video segmentation methods as well as a quantitative set of 2D and 3D metrics for good supervoxels.
Graph-Shifts Code (Java)
and
example data.
Video label propagation code and benchmark data set.
UB/College Park stereo building facade dataset. [more information].
Miscellaneous
|
News and Events

|
