Current Projects
- BlinkML : Approximate Model Training with Probabilistic Guarantees
- Database Learning : Query Engines that Become Smarter Every Time
- Infinite-Scale Analytics : Reducing Computational Footprint with Approximate Query Processing
- Designing a Predictable Database : Reducing Tail Latencies in Modern Data-Intensive Applications
Past Projects
- Conflux : A Low-Latency Data Platform for Computational Physics
- CliffGuard : A Principled Framework for Applying Robust Optimization Theory to Database Systems
- DBSeer : Self-Driving Databases
- Crowdsourcing Big Data
- BlinkDB : Querying Petabytes of Data in a Blink Time!
- High-Performance Complex Event Processing
- SMM: Stream Mill Miner : A System for Mining Data Streams
- User Modeling
People: Barzan Mozafari, Yongjoo Park
With the increase of dataset
volumes, training machine learning (ML) models has become a major computational
cost in most organizations. Given the iterative nature of model and parameter
tuning, many analysts use a small sample of their entire data during their
initial stage of analysis to make quick decisions on which direction to take
(e.g., whether and what types of features to add, what type of model to
pursue), and use the entire dataset only in later stages (i.e., when they have
converged to speci c model). This sampling, however, is performed in an ad-hoc
fashion. Most practitioners are not able to precisely capture the effect of sampling
on the quality of their model, and eventually on their decision making process
during the tuning phase. Moreover, without a systematic support for sampling
operators, many optimization and reuse opportunities are lost.
In BlinkML project, users are
allowed to make error-computation tradeoffs: instead of training a model on
their full data (i.e., full model), they can train on a smaller sample and thus
obtain an approximate model. With BlinkML, however, they can explicitly control
the quality of their approximate model by either (i) specifying an upper bound
on how much the approximate model is allowed to deviate from the full model, or
(ii) inquiring about the minimum sample size using which the trained model
would meet a given accuracy requirement.
Publications:
- Yongjoo Park, Jingyi Qing, Xiaoyang Shen, and Barzan Mozafari.
BlinkML: Efficient Maximum Likelihood Estimation with Probabilistic Guarantees. In Proceedings of the ACM SIGMOD 2019 Conference, Amsterdam, Netherlands, June 30 - July 05, 2019
Technical Report
People: Barzan Mozafari, Yongjoo Park, Michael Cafarella
In today’s databases, previous query answers rarely benefit answering future queries. For the first time, to the best of our knowledge, we change this paradigm in an approximate query processing (AQP) context. We make the following observation: the answer to each query reveals some degree of knowledge about the answer to another query because their answers stem from the same underlying distribution that has produced the entire dataset. Exploiting and refining this knowledge should allow us to answer queries more analytically, rather than by reading enormous amounts of raw data. Also, processing more queries should continuously enhance our knowledge of the underlying distribution, and hence lead to increasingly faster response times for future queries. We call this novel idea—learning from past query answers— Database Learning. Our experiments on real-world query traces show that Database Learning speeds up queries by up to 23x.
Publications:
Query Rewriting via Large Language Models. In Arxiv, 2024 - Barzan Mozafari, Radu Alexandru Burcuta, Alan Cabrera, Andrei Constantin, Derek Francis, David Grömling, Alekh Jindal, Maciej Konkolowicz, Valentin Marian Spac, Yongjoo Park, Russell Razo Carranza, Ni.
Making Data Clouds Smarter at Keebo: Automated Warehouse Optimization using Data Learning. In Proceedings of In Proceedings of the ACM SIGMOD 2023 Conference, Seattle, WA, USA, June 18-23, 2023
Try out Keebo- Yongjoo Park, Shucheng Zhong, and Barzan Mozafari.
QuickSel: Quick Selectivity Learning with Mixture Models. In Proceedings of the ACM SIGMOD Conference, Portland, Oregon, USA, June 14-19, 2020 - Yongjoo Park, Ahmad Shahab Tajik, Michael Cafarella, Barzan Mozafari.
Database Learning: Toward a Database that Becomes Smarter Every Time. In Proceedings of the ACM SIGMOD 2017 Conference, Chaminade, CA, United States, May 14-19, 2017
Download Verdict- Yongjoo Park, Ahmad Shahab Tajik, Michael Cafarella, and Barzan Mozafari.
Database Learning: Toward a Database that Becomes Smarter Every Time. Technical Report, April, 2016 - Yongjoo Park, Michael Cafarella, Barzan Mozafari.
Neighbor-Sensitive Hashing. In Proceedings of the 41st International Conference on Very Large Data Bases (PVLDB), New Delhi, India, September 05-09, 2016
Download the Source Code for NSH- Barzan Mozafari.
Verdict: A System for Stochastic Query Planning. In Proceedings of the Conference on Innovative Data Systems Research (CIDR), Asilomar, California, U.S.A., January, 2015
Website: http://verdictdb.org
People: Barzan Mozafari, Yongjoo Park, Rui Liu

Query optimization over the past four decades has been based on three assumptions: (A1) the goal is to efficiently access all relevant tuples and avoid the irrelevant ones; (A2) the decision is to choose the cheapest query plan among a set of equivalent plans; and (A3) the work (I/O and computation) performed for answering a query is completely wasted afterwards. In this project, we challenge all three assumptions, demonstrating that this traditional approach is both unnecessary and increasingly impractical. For example, indexing, pre-computation, columnar compression, and in-memory structures all insist on processing every relevant tuple (A1), and are thus destined to fail. This is because data volumes are growing exponentially faster than Moore’s law, implying that our inability to provide interactive response times (e.g., due to network costs and Memory Wall) will only worsen over time. We also make the observation that forgoing A1 is the only viable alternative: processing only a small sample of relevant tuples yields fast approximate answers, the accuracy of which depends only on the size of the sample itself (not the overall dataset). This observation implies that approximation techniques are the only solutions that are infinitely scalable in the long-term (same sample size, faster hardware). We also show that perfect decisions are in many cases possible without perfect answers (e.g., visualization, A/B testing, k-nearest neighbors, feature selection, exploratory analytics, etc.). Furthermore, forgoing A2, by pursuing multiple plans that are not equivalent, dramatically reduces error. Finally, to overcome the ultimate limitation of today’s databases (A3), we propose a new research direction, called Database Learning, which allows databases to become smarter and faster over time. The answer to each query reveals some knowledge of the underlying distribution, which we can exploit to answer other queries more analytically (thus, reading less and less data).
The ultimate goal of this project to allow for any existing database to benefit from approximation techniques, without requiring any changes to their internal implementation. We have open-sourced a prototype of this universal solution at http://VerdictDB.org
Publications:
Joins on Samples: A Theoretical Guide for Practitioners. In Proceedings of 46th International Conference on Very Large Databases (PVLDB), Tokyo, Japan, August 31 - September 04, 2020
Technical Report- Yongjoo Park, Jingyi Qing, Xiaoyang Shen, and Barzan Mozafari.
BlinkML: Efficient Maximum Likelihood Estimation with Probabilistic Guarantees. In Proceedings of the ACM SIGMOD 2019 Conference, Amsterdam, Netherlands, June 30 - July 05, 2019
Technical Report- Jarrid Rector-Brooks, Jun-Kun Wang, and Barzan Mozafari.
Revisiting Projection-Free Optimization for Strongly Convex Constraint Sets. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, January 27 - February 01, 2019
Technical Report- Rui Liu, Tianyi Wu, and Barzan Mozafari.
A Bandit Approach to Maximum Inner Product Search. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, January 27 - February 01, 2019 - Barzan Mozafari.
SnappyData. In Encyclopedia of Big Data Technologies, Springer, Cham, 2018
Download SnappyData- Dong Young Yoon, Mosharaf Chowdhury, and Barzan Mozafari.
Distributed Lock Management with RDMA: Decentralization without Starvation. In Proceedings of the ACM SIGMOD 2018 Conference, Houston, TX, USA, June 10-15, 2018 - Yongjoo Park, Barzan Mozafari, Joseph Sorenson, and Junhao Wang.
VerdictDB: Universalizing Approximate Query Processing. In Proceedings of the ACM SIGMOD 2018 Conference, Houston, TX, USA, June 10-15, 2018
Download the latest release- Wen He, Yongjoo Park, Idris Hanafi, Jacob Yatvitskiy, and Barzan Mozafari.
Demonstration of VerdictDB, the Platform-Independent AQP System. In Proceedings of the ACM SIGMOD 2018 Conference, Houston, TX, USA, June 10-15, 2018
Download VerdictDB
Watch a video- Barzan Mozafari.
Approximate Query Engines: Commercial Challenges and Research Opportunities. In Proceedings of the ACM SIGMOD 2017 Conference, Chicago, IL, United States, May 14-19, 2017
(Keynote) Slides- Yongjoo Park, Ahmad Shahab Tajik, Michael Cafarella, Barzan Mozafari.
Database Learning: Toward a Database that Becomes Smarter Every Time. In Proceedings of the ACM SIGMOD 2017 Conference, Chaminade, CA, United States, May 14-19, 2017
Download Verdict- Barzan Mozafari, Jags Ramnarayan, Sudhir Menon, Yogesh Mahajan, Soubhik Chakraborty, Hemant Bhanawat, Kishor Bachhav.
SnappyData: A Unified Cluster for Streaming, Transactions and Interactice Analytics. In Proceedings of Conference on Innovative Data Systems Research (CIDR), Chaminade, CA, United States, January 08-11, 2017
Spin out an iSight cloud for free!
Download Our Latest Release- Jags Ramnarayan, Barzan Mozafari, Sumedh Wale, Sudhir Menon, Neeraj Kumar, Hemant Bhanawat, Soubhik Chakraborty, Yogesh Mahajan, Rishitesh Mishra, Kishor Bachhav.
SnappyData: A Hybrid Transactional Analytical Store Built On Spark. In Proceedings of the ACM SIGMOD 2016 Conference, San Francisco, CA, USA, June 26 - July 01, 2016
Download the Source Code for SnappyData- Yongjoo Park, Ahmad Shahab Tajik, Michael Cafarella, and Barzan Mozafari.
Database Learning: Toward a Database that Becomes Smarter Every Time. Technical Report, April, 2016 - Jags Ramnarayan, Barzan Mozafari, Sudhir Menon, Sumedh Wale, Neeraj Kumar, Hemant Bhanawat, Soubhik Chakraborty, Yogesh Mahajan, Rishitesh Mishra, and Kishor Bachhav.
SnappyData: Streaming, Transactions, and Interactive Analytics in a Unified Engine. Technical Report, March, 2016 - Yongjoo Park, Michael Cafarella, Barzan Mozafari.
Neighbor-Sensitive Hashing. In Proceedings of the 41st International Conference on Very Large Data Bases (PVLDB), New Delhi, India, September 05-09, 2016
Download the Source Code for NSH- Yongjoo Park, Michael Cafarella, Barzan Mozafari.
Visualization-Aware Sampling for Very Large Databases. In Proceedings of 32nd IEEE International Conference on Data Engineering (ICDE), Helsinki, Finland, May 16-20, 2016
Technical Report- Barzan Mozafari, and Ning Niu.
A Handbook for Building an Approximate Query Engine. IEEE Data Engineering Bulletin, October, 2015 - Barzan Mozafari.
Verdict: A System for Stochastic Query Planning. In Proceedings of the Conference on Innovative Data Systems Research (CIDR), Asilomar, California, U.S.A., January, 2015 - Kai Zeng, Shi Gao, Barzan Mozafari and Carlo Zaniolo.
The Analytical Bootstrap: a New Method for Fast Error Estimation in Approximate Query Processing. In Proceedings of the ACM SIGMOD 2014 Conference, Snowbird, UT, U.S.A., June, 2014
Download the Error Estimation Source Code for SQL Queries (I)
Download the Error Estimation Source Code for SQL Queries (II)- Sameer Agarwal, Henry Milner, Ariel Kleiner, Ameet Talwalkar, Michael Jordan, Samuel Madden, Barzan Mozafari and Ion Stoica.
Knowing When You're Wrong: Building Fast and Reliable Approximate Query Processing Systems. In Proceedings of the ACM SIGMOD 2014 Conference, Snowbird, UT, U.S.A., June, 2014 - Kai Zeng, Shi Gao, Jiaqi Gu, Barzan Mozafari and Carlo Zaniolo.
ABS: a System for Scalable Approximate Queries with Accuracy Guarantees. In Proceedings of the ACM SIGMOD 2014 Conference, Snowbird, UT, U.S.A., June, 2014
(ACM SIGMOD's Best Demo Award) Download ABS (A General Approximate Query Engine with Error Estimation)
Download the Hive modifications for ABS- Sameer Agarwal, Barzan Mozafari, Aurojit Panda, Henry Milner, Samuel Madden, and Ion Stoica.
BlinkDB: Queries with Bounded Errors and Bounded Response Times on Very Large Data. In Proceedings of the European Conference on Computer Systems (EuroSys), Prague, Czech Republic, April 14-17, 2013
(Best Paper Award) Download BlinkDB's official release.- Sameer Agarwal, Aurojit Panda, Barzan Mozafari, Anand P. Iyer, Samuel Madden, and Ion Stoica.
Blink and It's Done: Interactive Queries on Very Large Data. In Proceedings of the 38th International Conference on Very Large Data Bases (PVLDB), Istanbul, Turkey, August 27-31, 2012
Download BlinkDB's official release.- Barzan Mozafari and Carlo Zaniolo.
Optimal Load Shedding with Aggregates and Mining Queries. In Proceedings of the 26th International Conference on Data Engineering (ICDE), Long Beach, California, U.S.A., March 01-06, 2010
Designing a Predictable Database
Website: https://web.eecs.umich.edu/~mozafari/predictabledb/
People: Barzan Mozafari, Dong Young Yoon, Grant Schoenebeck, Jiamin Huang, Thomas Wenisch
Four decades of research on database systems has mostly focused on improving average raw performance. This competition for faster performance has, understandably, neglected predictability of our database management systems. However, as database systems have become more complex, their erratic and unpredictable performance has become a major challenge facing database users and administrators alike. With the increasing reliance of mission-critical business applications on their databases, maintaining high levels of database performance (i.e., service level guarantees) is now more important than ever. Cloud users find it challenging to provision and tune their database instances, due to the highly non-linear and unpredictable nature of today's databases. Even for deployed databases, performance tuning has become somewhat of a black art, rendering qualified database administrators a scare resource. In this project, we restore the missing virtue of predictability in the design of database systems. First, we quantify the major sources of uncertainty in a database in a principled manner. Then, by rethinking the traditional design of a database system, we architect a new generation of databases that treat predictability as a first class-citizen in their various stages of query processing, from physical design to memory management and query scheduling. Moreover, to accommodate existing database systems (which are not predictable by design), we provide effective tools and methodologies for predicting their performance more accurately. Building a predictable database in a bottom-up fashion and in a principled manner, offers great insight into improving existing database products and can instigate a radical shift in the way that future databases are designed and implemented.
Publications:
Distributed Lock Management with RDMA: Decentralization without Starvation. In Proceedings of the ACM SIGMOD 2018 Conference, Houston, TX, USA, June 10-15, 2018 - Boyu Tian, Jiamin Huang, Barzan Mozafari, and Grant Schoenebeck.
Contention-aware lock scheduling for transactional databases. In Proceedings of 44th International Conference on Very Large Databases (PVLDB), Rio de Janeiro, Brazil, August 27-31, 2018
(Adopted by MySQL 8.0.3+) Technical Report- Jiamin Huang, Barzan Mozafari and Thomas F. Wenisch.
Statistical Analysis of Latency Through Semantic Profiling. In Proceedings of the European Conference on Computer Systems (EuroSys), Belgrade, Serbia, April 23-26, 2017
Download VProfiler's Latest Release- Jiamin Huang, Barzan Mozafari, Grant Schoenebeck, Thomas F. Wenisch.
A Top-Down Approach to Achieving Performance Predictability in Database Systems. In Proceedings of the ACM SIGMOD 2017 Conference, Chicago, IL, United States, May 14-19, 2017
Slides- Jiamin Huang, Barzan Mozafari, Grant Schoenebeck, and Thomas Wenisch.
Identifying the Major Sources of Variance in Transaction Latencies: Towards More Predictable Databases. In Technical Report, March, 2016 - Dong Young Yoon, Barzan Mozafari, and Douglas P. Brown.
DBSeer: Pain-free Database Administration through Workload Intelligence. In Proceedings of the 41st International Conference on Very Large Data Bases (PVLDB), Kohala Coast, Hawai'i, U.S.A., September 01-04, 2015
Watch a Video Demo of DBSeer
Download DBSeer's Latest Release- Barzan Mozafari, Eugene Zhen Ye Goh, and Dong Young Yoon.
CliffGuard: A Principled Framework for Finding Robust Database Designs. In Proceedings of the ACM SIGMOD 2015 Conference, Melbourne, VIC, Australia, May 31 - June 04, 2015
Visit our project's website
Download CliffGuard's Open-source Release
People: Barzan Mozafari, Karthik Duraisamy, Krishna Garikipati
This project develops an instrument, called ConFlux, hosted at the University of Michigan (UM), specifically designed to enable High Performance Computing (HPC) clusters to communicate seamlessly and at interactive speeds with data-intensive operations. The project establishes a hardware and software ecosystem to enable large scale data-driven modeling of multiscale physical systems. ConFlux will produce advances in predictive modeling in several disciplines including turbulent flows, materials physics, cosmology, climate science and cardiovascular flow modeling. A wide range of phenomena exhibit emergent behavior that makes modeling very challenging. In this project, physics-constrained data-driven modeling approaches are pursued to account for the underlying complexity. These techniques require HPC applications (running on external clusters) to interact with large data sets at run time. ConFlux provides low latency communications for in- and out-of-core data, cross-platform storage, as well as high throughput interconnects and massive memory allocations. The file-system and scheduler natively handle extreme-scale machine learning and traditional HPC modules in a tightly integrated workflow---rather than in segregated operations--leading to significantly lower latencies, fewer algorithmic barriers and less data movement. The funding for this project is $3.46M, out of which NSF and University of Michigan have each generously provided $2.4M and $1M, respectively.
News: $3.46M to combine supercomputer simulations with big data 08/15/2015
NSF and University of Michigan have jointly sponsored our ConFlux project: a massively parallel system for solving open problems in computational physics using large-scale machine learning! See the official news release here: http://www.engin.umich.edu/college/about/news/stories/2015/september/supercomputer-simulations-with-big-data
Publications:
Distributed Lock Management with RDMA: Decentralization without Starvation. In Proceedings of the ACM SIGMOD 2018 Conference, Houston, TX, USA, June 10-15, 2018 - Yongjoo Park, Ahmad Shahab Tajik, Michael Cafarella, Barzan Mozafari.
Database Learning: Toward a Database that Becomes Smarter Every Time. In Proceedings of the ACM SIGMOD 2017 Conference, Chaminade, CA, United States, May 14-19, 2017
Download Verdict- Yongjoo Park, Michael Cafarella, Barzan Mozafari.
Neighbor-Sensitive Hashing. In Proceedings of the 41st International Conference on Very Large Data Bases (PVLDB), New Delhi, India, September 05-09, 2016
Download the Source Code for NSH- Yongjoo Park, Michael Cafarella, Barzan Mozafari.
Visualization-Aware Sampling for Very Large Databases. In Proceedings of 32nd IEEE International Conference on Data Engineering (ICDE), Helsinki, Finland, May 16-20, 2016
Technical Report
Website: http://cliffguard.org
People: Barzan Mozafari, Dong Young Yoon
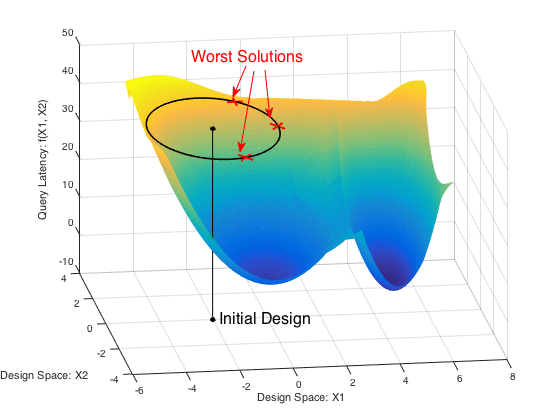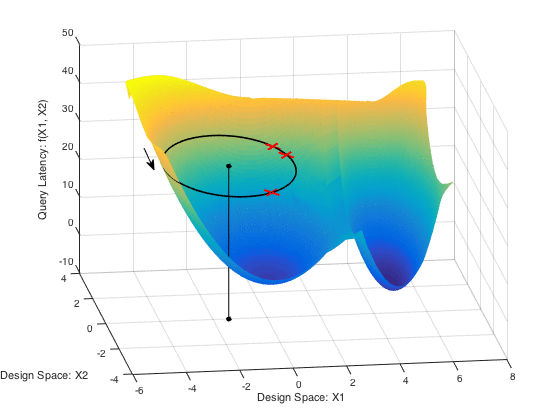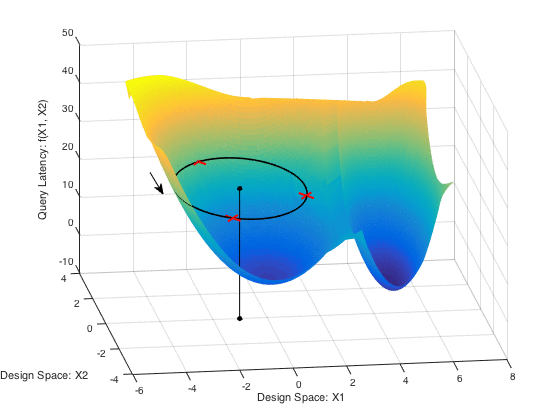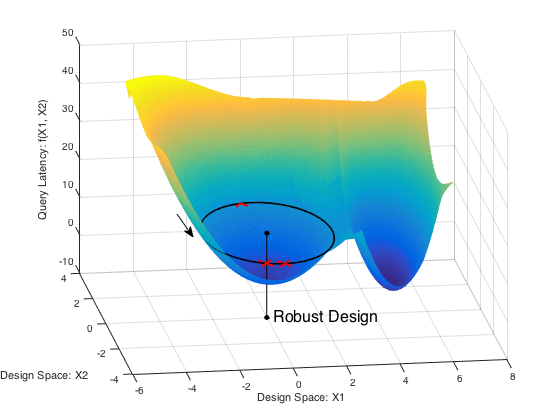
A fundamental problem in database systems is choosing the best physical design, i.e., a small set of auxiliary structures that enable the fastest execution of future queries. Modern databases come with designer tools that create a number of indices or materialized views, but they find designs that are sub-optimal and remarkably brittle. This is because future workload is often not known a priori and these tools optimize for past workloads in hopes that future queries and data will be similar. In practice, these input parameters are often noisy or missing.
CliffGuard is a practical framework that creates robust designs that are immune to parameter uncertainties as much as desired. CliffGuard is the first attempt at applying robust optimization theory in Operations Research to building a practical framework for solving one of the most fundamental problems in databases, namely finding the best physical design.
Publications:
CliffGuard: A Principled Framework for Finding Robust Database Designs. In Proceedings of the ACM SIGMOD 2015 Conference, Melbourne, VIC, Australia, May 31 - June 04, 2015
Visit our project's website
Download CliffGuard's Open-source Release
Website: http://dbseer.org/
People: Barzan Mozafari, Dong Young Yoon
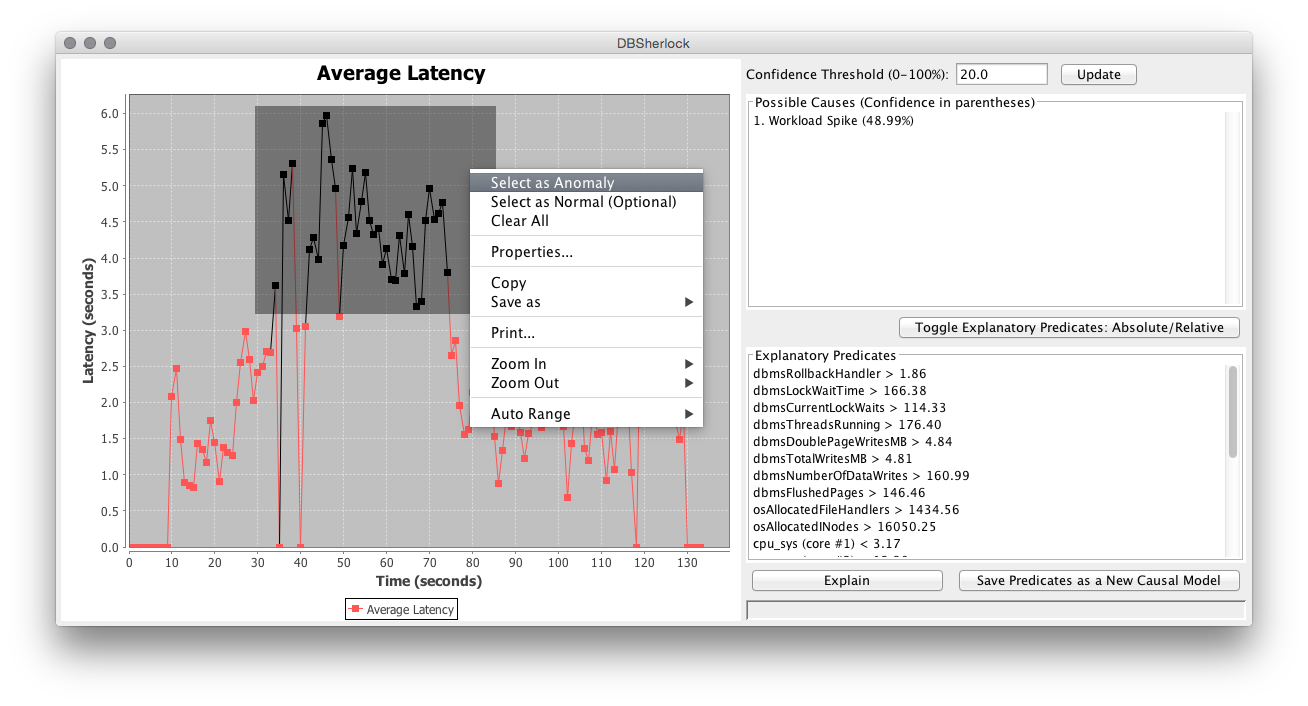
The pressing need for achieving and maintaining high performance in database systems has made database administration one of the most stressful jobs in information technology. DBAs are now responsible for an array of demanding tasks; they need to (i) provision and tune their database according to their application requirements, (ii) constantly monitor their database for any performance failures or slowdowns, (iii) diagnose the root cause of the performance problem in an accurate and timely fashion, and (iv) take prompt actions that can restore acceptable database performance. However, much of the research in the past years has focused on improving the raw performance of the database systems, rather than improving their manageability. DBSeer is a workload intelligence framework that exploits advanced machine learning and causality techniques to aid DBAs in their various responsibilities. DBSeer analyzes large volumes of statistics and telemetry data collected from various log files to provide the DBA with a suite of rich functionalities including performance prediction, performance diagno sis, bottleneck explanation, workload insight, optimal admission control, and what-if analysis.
News: Our paper got in CIDR 2013!
CIDR is based on a revolutionary vision which is quite different than the mainstream database conferences. This is what their website says: The biennial Conference on Innovative Data Systems Research (CIDR) is a systems-oriented conference, complementary in its mission to the mainstream database conferences like SIGMOD and VLDB, emphasizing the systems architecture perspective. CIDR gathers researchers and practitioners from both academia and industry to discuss the latest innovative and visionary ideas in the field. DBSeer is now accepted in CIDR's Outrageous Ideas and Vision Track. I am looking forward to presenting our DBSeer in January 2013!News: News: DBSeer's monitoring module is now open-source!
Download it from here. Email me if you run into any issues.News: Teradata has assigned a team of engineers to incorporate DBSeer into their framework!
Teradata is a leading provider of enterprise analytic technologies and services that include Data Warehousing, Business Intelligence and CRM. A few months ago I presented DBSeer at Dagstuhl's Database Workload Management Workshop which is where I met a member of Teradata's workload management team. Long story short, as a result of the meetings that followed (between the Teradata's technical managers and I), Teradata has decided to port DBSeer into their framework with the goal of automating their workload management mechanisms, which are currently based on manual configuration of a set of rules (called throttles). Exciting news is that with the allocation of engineering resources at Teradata to this project, the adoption of DBSeer into their framework has now officially started! I am already excited and looking forward to this collaboration and to see DBSeer's applications in a large commercial database system!News: Our paper got in SIGMOD 2013!
The annual ACM SIGMOD/PODS conference is a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results, and to exchange techniques, tools, and experiences. The full version of our DBSeer paper is now accepted in SIGMOD 2013, and I am looking forward to presenting DBSeer in June 2013! Recently I have been traveling a lot, so I am extra excited that this year's SIGMOD is held somewhere close to Boston (it is held in New York)!News: DBSeer in the press!
DBSeer has received considerable coverage from the press soon after MIT News Office did a story on DBSeer! Read more here.
Publications:
DBSherlock: A Performance Diagnostic Tool for Transactional Databases. In Proceedings of the ACM SIGMOD 2016 Conference, San Francisco, CA, USA, June 26 - July 01, 2016
Download the Datasets used in the Paper
Download the Source Code for DBSherlock / DBSeer- Dong Young Yoon, Barzan Mozafari, and Douglas P. Brown.
DBSeer: Pain-free Database Administration through Workload Intelligence. In Proceedings of the 41st International Conference on Very Large Data Bases (PVLDB), Kohala Coast, Hawai'i, U.S.A., September 01-04, 2015
Watch a Video Demo of DBSeer
Download DBSeer's Latest Release- Barzan Mozafari, Eugene Zhen Ye Goh, and Dong Young Yoon.
CliffGuard: A Principled Framework for Finding Robust Database Designs. In Proceedings of the ACM SIGMOD 2015 Conference, Melbourne, VIC, Australia, May 31 - June 04, 2015
Visit our project's website
Download CliffGuard's Open-source Release- Barzan Mozafari, Carlo Curino, Alekh Jindal, and Samuel Madden.
Performance and Resource Modeling in Highly-Concurrent OLTP Workloads. In Proceedings of the ACM SIGMOD 2013 Conference, New York, NY, U.S.A, June 22-27, 2013
Download DBSeer and start using it (it's now open source)!- Barzan Mozafari, Carlo Curino, and Samuel Madden.
DBSeer: Resource and Performance Prediction for Building a Next Generation Database Cloud. In Proceedings of the Conference on Innovative Data Systems Research (CIDR), Asilomar, California, U.S.A., January 06-09, 2013
Download the code
People: Barzan Mozafari
Crowdsourcing has become a very popular means of performing tasks that require human intelligence. But what do you do when your dataset is too "big"? Imagine having to deal with web-scale data: there are hundreds of millions of daily tweets and images. Even if labeling each label costs a penny, your company will soon go bankrupt! We have started a new project here at MIT that aims to scale crowdsourcing to Big Data.
News: We have designed active learning algorithms to integrate machine learning into crowdsourcing workflows!
Read my post on ISTC's blog about how we have approached this problem.
Publications:
Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning. the 41st International Conference on Very Large Data Bases (PVLDB), Kohala Coast, Hawai'i, U.S.A., September 01-04, 2015
Download Our Extensible Active Learning System
Download the Active Learning and Crowdsourced Datasets (Sentiment Analysis for Tweets) Used in the Paper- Barzan Mozafari, Purnamrita Sarkar, Michael J. Franklin, Michael I. Jordan, and Samuel Madden.
Active Learning for Crowd-Sourced Databases. In Technical Report, 2013
Download the Active Learning and Crowdsourced Datasets (Sentiment Analysis for Tweets) Used in the Paper
Website: http://blinkdb.org/
People: Barzan Mozafari
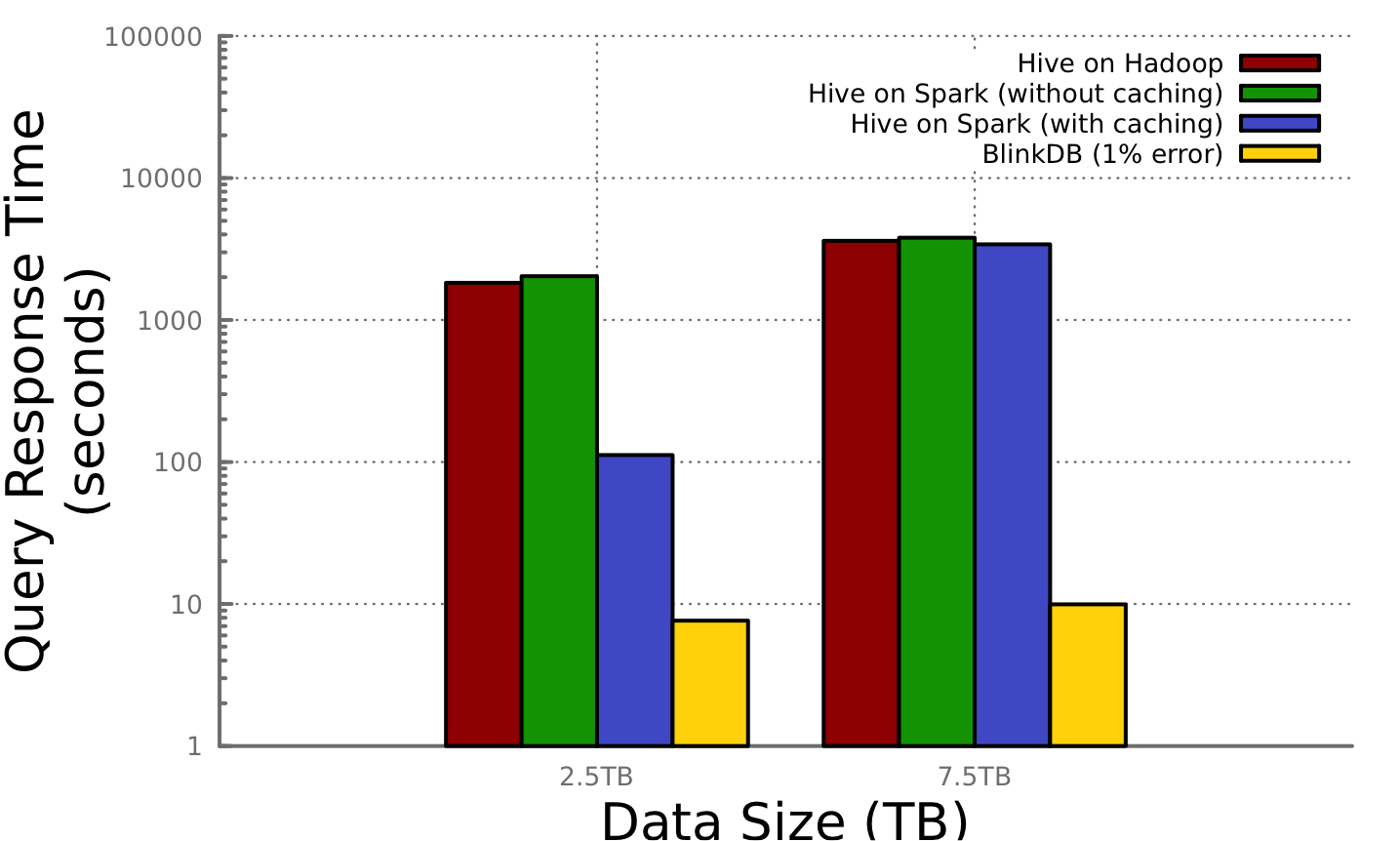
Today's web is predominantly data-driven. People increasingly depend on enormous amounts of data (spanning terabytes or even petabytes in size) to make intelligent business and personal decisions. Often the time it takes to make these decisions is critical. However, unfortunately, quickly analyzing large volumes of data poses significant challenges. For instance, scanning 1TB of data may take minutes, even when the data is spread across hundreds of machines and read in parallel. BlinkDB is a massively parallel, sampling-based approximate query engine for running interactive queries on large volumes of data. The key observation in BlinkDB is that one can make perfect decisions in the absence of perfect answers. For example, reliably detecting a malfunctioning server in a distributed collection of system logs does not require knowing every request the server processed. Based on this insight, BlinkDB allows one to tradeoff between query accuracy and response time, enabling interactive queries over massive data by running queries on data samples. To achieve this, BlinkDB uses two key ideas that differentiate it from previous sampling-based database systems: (1) an optimization framework to build a set of multi-dimensional, multi-resolution samples, and (2) a strategy that uses a set of small samples to dynamically estimate a query's error and response time at run-time. We have built a BlinkDB prototype, and validate its effectiveness using well-known benchmarks and a real-world workload derived from Conviva. Our initial set of experiments show that BlinkDB can execute a range of queries over a real-world query trace on up to 17 TB of data and 100 nodes in 2 seconds, with an error of 2-10%.
News: BlinkDB is now open source!
Download our latest release from http://blinkdb.orgNews: BlinkDB demo at the first BigData@CSAIL retreat!
I gave a demo of BlinkDB at the 1'st annual bigdata@csail member meeting. On November 28, 2012, about 40 managers and researchers from 8 founding member of bigdata@csail attended this meeting including -- AIG, EMC, Huawei, Intel, Microsoft, Samsung, SAP and Thomson Reuters -- and the MIT CSAIL research community. Our demo caused a lot of excitement! The audience loved it when they saw they could query 10TB of data in less than 2 seconds:)News: Facebook is deploying BlinkDB!
According to the latest news, Facebook is scheduled to deploy and explore our BlinkDB on one of their 80-node clusters in February 2013. BlinkDB is built upon and is backward compatible with Hive/Hadoop. Given that Facebook is the main contributor to Hive, this is a great news for the BlinkDB team:) Go BlinkDB!News: Our recent submission to EuroSys 2013 got in!
Looking forward to going to Prague and get some feedback on our BlinkDB from the systems community.News: News: BlinkDB won the Best Paper Award in EuroSys 2013!
Congratulations to the BlinkDB team!
Publications:
VerdictDB: Universalizing Approximate Query Processing. In Proceedings of the ACM SIGMOD 2018 Conference, Houston, TX, USA, June 10-15, 2018
Download the latest release- Wen He, Yongjoo Park, Idris Hanafi, Jacob Yatvitskiy, and Barzan Mozafari.
Demonstration of VerdictDB, the Platform-Independent AQP System. In Proceedings of the ACM SIGMOD 2018 Conference, Houston, TX, USA, June 10-15, 2018
Download VerdictDB
Watch a video- Barzan Mozafari.
Approximate Query Engines: Commercial Challenges and Research Opportunities. In Proceedings of the ACM SIGMOD 2017 Conference, Chicago, IL, United States, May 14-19, 2017
(Keynote) Slides- Yongjoo Park, Ahmad Shahab Tajik, Michael Cafarella, Barzan Mozafari.
Database Learning: Toward a Database that Becomes Smarter Every Time. In Proceedings of the ACM SIGMOD 2017 Conference, Chaminade, CA, United States, May 14-19, 2017
Download Verdict- Barzan Mozafari, Jags Ramnarayan, Sudhir Menon, Yogesh Mahajan, Soubhik Chakraborty, Hemant Bhanawat, Kishor Bachhav.
SnappyData: A Unified Cluster for Streaming, Transactions and Interactice Analytics. In Proceedings of Conference on Innovative Data Systems Research (CIDR), Chaminade, CA, United States, January 08-11, 2017
Spin out an iSight cloud for free!
Download Our Latest Release- Jags Ramnarayan, Barzan Mozafari, Sumedh Wale, Sudhir Menon, Neeraj Kumar, Hemant Bhanawat, Soubhik Chakraborty, Yogesh Mahajan, Rishitesh Mishra, Kishor Bachhav.
SnappyData: A Hybrid Transactional Analytical Store Built On Spark. In Proceedings of the ACM SIGMOD 2016 Conference, San Francisco, CA, USA, June 26 - July 01, 2016
Download the Source Code for SnappyData- Yongjoo Park, Ahmad Shahab Tajik, Michael Cafarella, and Barzan Mozafari.
Database Learning: Toward a Database that Becomes Smarter Every Time. Technical Report, April, 2016 - Jags Ramnarayan, Barzan Mozafari, Sudhir Menon, Sumedh Wale, Neeraj Kumar, Hemant Bhanawat, Soubhik Chakraborty, Yogesh Mahajan, Rishitesh Mishra, and Kishor Bachhav.
SnappyData: Streaming, Transactions, and Interactive Analytics in a Unified Engine. Technical Report, March, 2016 - Yongjoo Park, Michael Cafarella, Barzan Mozafari.
Neighbor-Sensitive Hashing. In Proceedings of the 41st International Conference on Very Large Data Bases (PVLDB), New Delhi, India, September 05-09, 2016
Download the Source Code for NSH- Yongjoo Park, Michael Cafarella, Barzan Mozafari.
Visualization-Aware Sampling for Very Large Databases. In Proceedings of 32nd IEEE International Conference on Data Engineering (ICDE), Helsinki, Finland, May 16-20, 2016
Technical Report- Barzan Mozafari, and Ning Niu.
A Handbook for Building an Approximate Query Engine. IEEE Data Engineering Bulletin, October, 2015 - Barzan Mozafari.
Verdict: A System for Stochastic Query Planning. In Proceedings of the Conference on Innovative Data Systems Research (CIDR), Asilomar, California, U.S.A., January, 2015 - Kai Zeng, Shi Gao, Barzan Mozafari and Carlo Zaniolo.
The Analytical Bootstrap: a New Method for Fast Error Estimation in Approximate Query Processing. In Proceedings of the ACM SIGMOD 2014 Conference, Snowbird, UT, U.S.A., June, 2014
Download the Error Estimation Source Code for SQL Queries (I)
Download the Error Estimation Source Code for SQL Queries (II)- Sameer Agarwal, Henry Milner, Ariel Kleiner, Ameet Talwalkar, Michael Jordan, Samuel Madden, Barzan Mozafari and Ion Stoica.
Knowing When You're Wrong: Building Fast and Reliable Approximate Query Processing Systems. In Proceedings of the ACM SIGMOD 2014 Conference, Snowbird, UT, U.S.A., June, 2014 - Kai Zeng, Shi Gao, Jiaqi Gu, Barzan Mozafari and Carlo Zaniolo.
ABS: a System for Scalable Approximate Queries with Accuracy Guarantees. In Proceedings of the ACM SIGMOD 2014 Conference, Snowbird, UT, U.S.A., June, 2014
(ACM SIGMOD's Best Demo Award) Download ABS (A General Approximate Query Engine with Error Estimation)
Download the Hive modifications for ABS- Sameer Agarwal, Barzan Mozafari, Aurojit Panda, Henry Milner, Samuel Madden, and Ion Stoica.
BlinkDB: Queries with Bounded Errors and Bounded Response Times on Very Large Data. In Proceedings of the European Conference on Computer Systems (EuroSys), Prague, Czech Republic, April 14-17, 2013
(Best Paper Award) Download BlinkDB's official release.- Sameer Agarwal, Aurojit Panda, Barzan Mozafari, Anand P. Iyer, Samuel Madden, and Ion Stoica.
Blink and It's Done: Interactive Queries on Very Large Data. In Proceedings of the 38th International Conference on Very Large Data Bases (PVLDB), Istanbul, Turkey, August 27-31, 2012
Download BlinkDB's official release.
High-Performance Complex Event Processing
People: Barzan Mozafari, Kai Zeng, Carlo Zaniolo

Complex Event Processing (CEP) is a broad term, referring to any application that involves searching for complex patterns among raw events to infer higher-level concepts. Examples include high-frequency trading (a certain correlation in stock prices that triggers a purchase), intrusion detection (a series of network activities that indicate an attack), inventory management (moving patterns using RFID or GPS readings), click stream analysis (a sequence of clicks that trigger an ad), and electronic health systems (a combination of sensor readings raising an alert). CEP applications have created a fast-growing market, with an annual growth rate of 30% (see Celent report). This growing market has led database vendors to add new constructs (called MATCH_RECOGNIZE) to the SQL language that allow for expressing sequential patterns among the rows in a table.
Seeking richer abstractions for supporting CEP applications, we have introduced constructs based on Kleene-closure expressions and showed that they are significantly more powerful than those proposed by database vendors (which are provably incapable of expressing many important CEP queries). We have designed the first two database query languages that used nested word automata (NWA) as their underlying computational model: K*SQL with a relational interface, and XSeq with an XML interface. NWAs are recent advances in the field of automata theory that generalize the notion of regular languages to capture data that has both sequential and hierarchical structures. Examples of such data are XML, JSON files, RNA proteins, and traces of procedural programs.
K*SQL solves the long-standing problem of providing a unified query engine for both relational and hierarchical data. Similarly, despite 15 years of previous research where using tree automata for XML optimization was the status quo, XSeq translates XML queries into NWAs (which are then optimized using my algorithms) and outperformes the state-of-the-art XML engines by several orders of magnitude. XSeq received the SIGMOD's best paper award in 2012.
News: Our paper on high-performance complex event processing won SIGMOD 2012's Best Paper Award!

News: Our comments were adopted into the US position for the next edition of SQL!
On March 13, 2013 most of my comments for the changes to the SQL standard (which were based on the papers we published in this area) were approved and adopted by the DM32.2 committee! The DM32.2 Task Group on Database develops standards for the syntax and semantics of database languages. This Task Group is the U.S. TAG to ISO/IEC JTC1/SC32/WG3 & WG4 and provides recommendations on U.S. positions to INCITS. I have been informed that (thanks to Fred Zemke) 3 out of my 4 comments on the recenetly proposed changes to SQL have been approved by the DM32.2 committee and will be deployed for the next edition of SQL standard. My comments are numbered 34, 35, and 36 in the following document. I am now an official contributor to the international SQL standards process!
Publications:
High-Performance Complex Event Processing over Hierarchical Data. In ACM TODS's Special Issue on, December, 2013 - Kai Zeng, Mohan Yang, Barzan Mozafari, and Carlo Zaniolo.
Complex Pattern Matching in Complex Structures: the XSeq Approach. In Proceedings of the 29th International Conference on Data Engineering (ICDE), Brisbane, Australia, April 08-11, 2013 - Barzan Mozafari, Kai Zeng, and Carlo Zaniolo.
High-Performance Complex Event Processing over XML Streams. In Proceedings of the ACM SIGMOD 2012 Conference, Scottsdale, Arizona, U.S.A., May 20-24, 2012
(Best Paper Award) Read the extended version here.- Barzan Mozafari, Kai Zeng, and Carlo Zaniolo.
From Regular Expressions to Nested Words: Unifying Languages and Query Execution for Relational and XML Sequences. In Proceedings of the 36th International Conference on Very Large Data Bases (PVLDB), Singapore, Singapore, September 12-17, 2010 - Barzan Mozafari, Kai Zeng, and Carlo Zaniolo.
K*SQL: A Unifying Engine for Sequence Patterns and XML. In Proceedings of the ACM SIGMOD 2010 Conference, Indianapolis, Indiana, U.S.A., June 06-11, 2010
(Honorable Mention Demo Award)
People: Barzan Mozafari, Carlo Zaniolo
Stream Mill Miner (SMM) is an extensible online data stream mining workbench. SMM is built upon a powerful data stream management system, namely StreamMill. Stream Mill is efficiently supports continuous queries, which are critical in many application areas, including sensors networks, traffic monitoring and intrusion detection. Stream Mill achieves a much broader range of usability and effectiveness in its application domain via minimal but powerful extensions to SQL. SMM utilizes these extensions to build an extensible online mining workbench. The main features of the SMM system are as follows:
- Extensibility that allows advanced users/analysts to integrate new mining algorithms, by implementing them declaratively. This feature is supported through Stream Mill UDAs, which are either defined natively in SQL or externally in a programming language such as C/C++. Stream Mill UDAs provide tremendous expressive power to the users, both theoretically and practically. Therefore, in SMM these UDAs implement complex mining algorithms. Thus, many new mining algorithms can be integrated into SMM using these features. Naive users can invoke both built-in and user defined mining algorithms with a unified syntax.
- A rich library of mining algorithms (a) that are fast and light enough to mine data streams, and (b) that dovetail with the constructs and mechanisms (windows, slides, etc.) is provided using the UDAs discussed above.
- Specification of workflows, which allows the advanced users/analysts to specify the complete end-to-end mining process. These workflows are also invoked using the same unified syntax, as discussed earlier. Workflows allow the analysts to develop complex mining processes, which are then simply invoked by naive users.
Publications:
SMM: a Data Stream Management System for Knowledge Discovery. In Proceedings of the 27th International Conference on Data Engineering (ICDE), Hannover, Germany, April 11-16, 2011 - Barzan Mozafari and Carlo Zaniolo.
Optimal Load Shedding with Aggregates and Mining Queries. In Proceedings of the 26th International Conference on Data Engineering (ICDE), Long Beach, California, U.S.A., March 01-06, 2010 - Hetal Thakkar, Barzan Mozafari and Carlo Zaniolo.
Continuous Post-Mining of Association Rules in a Data Stream Management System. In Post-Mining of Association Rules: Techniques for Effective Knowledge Extraction, edited by Yanchang Zhao, Chengqi Zhang, and Longbing Cao, Information Science Reference, - Barzan Mozafari, Hetal Thakkar, and Carlo Zaniolo.
Verifying and Mining Frequent Patterns from Large Windows over Data Streams. In Proceedings of the 24th International Conference on Data Engineering (ICDE), Cancun, Mexico, April 07-12, 2008
Download the source code for frequent pattern/itemset mining over data streams
Download the implementation for DTV and DFV verifiers- Hetal Thakkar, Barzan Mozafari and Carlo Zaniolo.
A Data Stream Mining System. In Proceedings of the International Conference on Data Mining ICDM 2008, Pisa, Italy, December 15-19, 2008

The overall goal of the BlogoCenter project was to develop innovative technologies to build a system that will (1) continuously monitor, collect, and store personal Weblogs (or blogs) at a central location, (2) discover hidden structures and trends automatically from the blogs, and (3) make them easily accessible to general users. By making the new information on the blogs easy to discover and access, this project aimed at helping blogs realize their full potential for societal change as the "grassroots media."
Publications:
Publishing Naive Bayesian Classifiers: Privacy without Accuracy Loss. In Proceedings of the 35th International Conference on Very Large Data Bases (PVLDB), Lyon, France, August 24-28, 2009 - Rodrigo B. Almeida, Barzan Mozafari, and Junghoo Cho.
On the Evolution of Wikipedia. In Proceedings of the International Conference on Weblogs and Social Media (ICWSM), Boulder, Colorado, U.S.A., March 26-28, 2007