Overview
For decades of research on database systems has mostly focused on improving average raw performance. This competition for faster performance has, understandably, neglected predictability of our database management systems. However, as database systems have become more complex, their erratic and unpredictable performance has become a major challenge facing database users and administrators alike. With the increasing reliance of mission-critical business applications on their databases, maintaining high levels of database performance (i.e., service level guarantees) is now more important than ever. Cloud users find it challenging to provision and tune their database instances, due to the highly non-linear and unpredictable nature of today's databases. Even for deployed databases, performance tuning has become somewhat of a black art, rendering qualified database administrators a scare resource. In this project, we restore the missing virtue of predictability in the design of database systems. First, we quantify the major sources of uncertainty in a database in a principled manner. Then, by rethinking the traditional design of a database system, we architect a new generation of databases that treat predictability as a first class-citizen in their various stages of query processing, from physical design to memory management and query scheduling. Moreover, to accommodate existing database systems (which are not predictable by design), we provide effective tools and methodologies for predicting their performance more accurately. Building a predictable database in a bottom-up fashion and in a principled manner, offers great insight into improving existing database products and can instigate a radical shift in the way that future databases are designed and implemented.
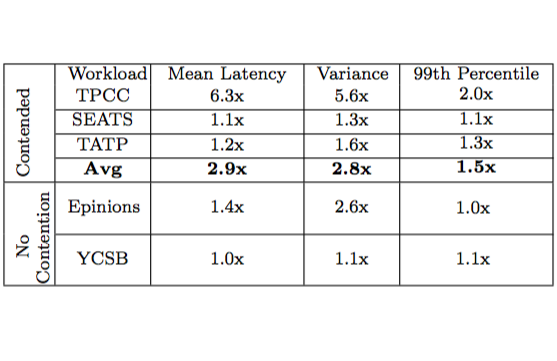 Improvement of VATS on 5 Workloads
Improvement of VATS on 5 Workloads
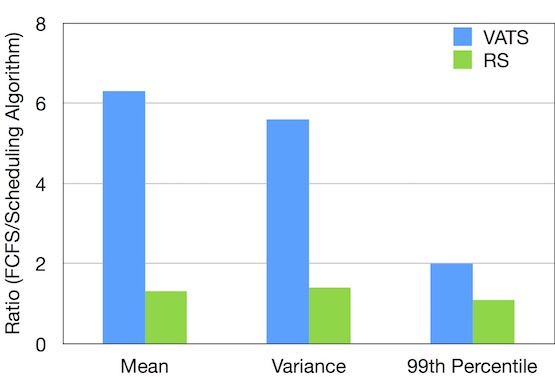 Improvement of VATS and RS on TPC-C
Improvement of VATS and RS on TPC-C
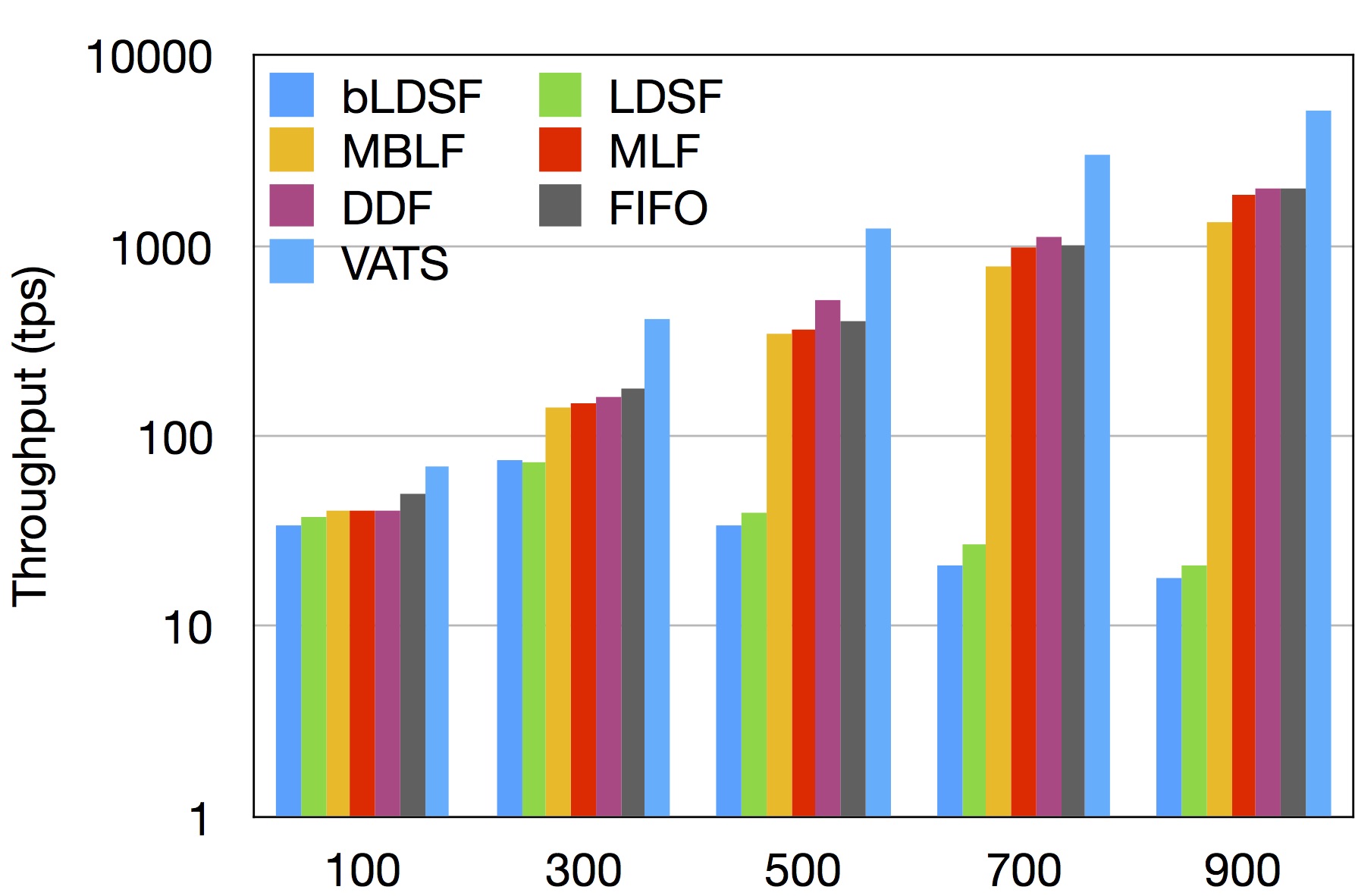
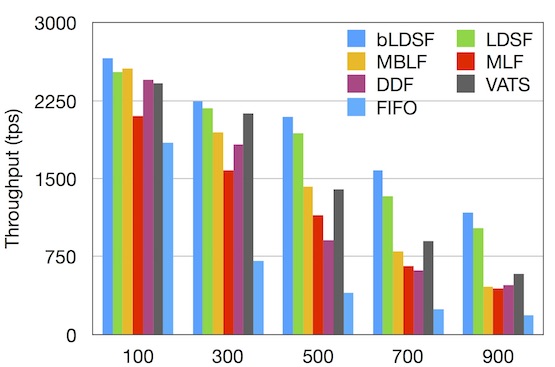 Maximum Throughput Under Various Algorithms (TPC-C)
Maximum Throughput Under Various Algorithms (TPC-C)
 Transaction Latency Under Various Algorithms (TPC-C)
Transaction Latency Under Various Algorithms (TPC-C)
