Today I hooded Dr. Javier Salazar Cavazos, who defended his thesis in March and today walked the stage at commencement. His dissertation is entitled “Learning Representations from Noisy Data and Brain Imaging: Subspace Modeling for Heteroscedastic Data and Deep Learning for Functional MRI in Alzheimer’s Disease,” and included his paper on ALPCAH, an algorithm for heteroscedastic subspace learning. Next he’ll be going to KLA. Congratulations Javier!
May 1, 2026
April 13, 2026
Signal Processing Magazine special issue on the Mathematics of Deep Learning
I am excited to say that our SPM special issue, part 1, on the Mathematics of Deep Learning, has now been published in ieee explore.
As we said in our guest editorial, “The aim of this special issue is to capture some of the salient points of contact between the SP and DL disciplines so that a mathematical picture of the key questions and challenges ahead begins to emerge.” The eight papers in this part of the issue all display these contact points beautifully: from sparsity to Kalman filtering to probability.
SPM is a venue that provides tutorial-like material on important signal processing topics. I hope you will read the issue and share the material with your junior graduate students.
December 8, 2025
SPADA lab at Neurips 2025
SPADA lab had two interesting works to share at Neurips this year. The first was MonarchAttention, which received a spotlight; thanks to everyone who stopped by the poster. See our earlier post for an example of how our method offers a zero-shot drop-in replacement for softmax attention at a significant savings of memory and computation – with very little accuracy loss. This technique has a University of Michigan patent pending.
The second work is on the topic of Out-of-Distribution In-Context Learning, which we presented at the What Can’t Transformers Do? Workshop. We analyze the solution for training linear attention on an out-of-distribution linear regression test task, where the training task is a regression vector either drawn from a single subspace or a union of subspaces. In the case of a union of subspaces, we can generalize to the span of the subspaces at test time.
Nice work to all the students: Can, Soo Min (both SPADA lab members), as well as our treasured collaborators Alec, Pierre, and Changwoo!
June 6, 2025
Monarch Attention
The attention module in transformer architectures is often the most computation and memory intensive unit. Many researchers have tried different ways to approximate softmax attention in a compute efficient way. We have a new approach that uses the Monarch matrix structure along with variational softmax to quickly and accurately approximate softmax attention in a zero-shot setting. The results are very exciting — we can significantly decrease the compute and memory requirements while taking at most a small hit to performance. This figure shows the performance versus computation of our “Monarch-Attention” method as compared to Flash Attention 2 (listed as “softmax”) and other fast approximations.
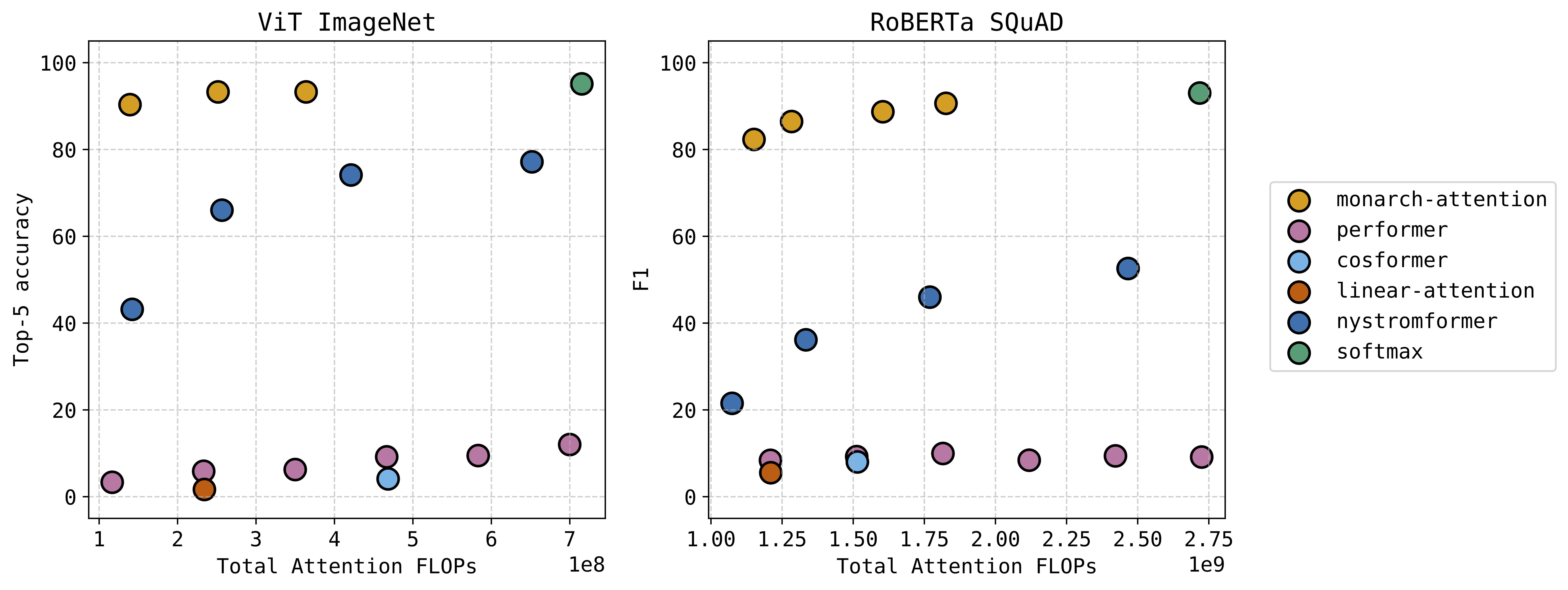
See the paper for additional results, including hardware benchmarking against Flash Attention 2 on several sequence lengths.
Can Yaras, Alec S. Xu, Pierre Abillama, Changwoo Lee, Laura Balzano. “MonarchAttention: Zero-Shot Conversion to Fast, Hardware-Aware Structured Attention.”
https://arxiv.org/abs/2505.18698
Code can be found here.
May 29, 2025
Analyzing Out-of-Distribution In-Context Learning
We posted a new paper on arxiv presenting analysis on the capabilities of attention for in-context learning. There are many perspectives out there on whether it’s possible to do in-context learning out-of-distribution: some papers show it’s possible, and others do not, mostly with empirical evidence. We provide some theoretical results in a specific setting, using linear attention to solve linear regression. We show a negative result that when the model is trained on a single subspace, the risk on out-of-distribution subspaces is lower bounded and cannot be driven to zero. Then we show that when the model is instead trained on a union-of-subspaces, the risk can be driven to zero on any test point in the span of the trained subspaces – even ones that have zero probability in the training set. We are hopeful that this perspective can help researchers improve the training process to promote out-of-distribution generalization.
Soo Min Kwon, Alec S. Xu, Can Yaras, Laura Balzano, Qing Qu. “Out-of-Distribution Generalization of In-Context Learning: A Low-Dimensional Subspace Perspective.” https://arxiv.org/abs/2505.14808.
April 19, 2025
SDP Relaxation paper in SIMAX
I’m excited that our paper “A Semidefinite Relaxation for Sums of Heterogeneous Quadratic Forms on the Stiefel Manifold” has been published in the SIAM Journal on Matrix Analysis and Applications. https://doi.org/10.1137/23M1545136. We were inspired to work on this problem after it popped up inside the heteroscedastic PCA problem. It’s a fascinating, simple, general problem with connections to PCA, joint diagonalization, and low-rank semidefinite programs. Applying the standard Schur relaxation to this problem gives a trivial (and incorrect) solution, but one minor change makes the relaxation powerful and even tight in many instances. You can find the code for experiments here.
February 11, 2025
Sarah Goddard Power Award
I am honored to have received the Sarah Goddard Power Award, an award given to those who contribute to the advancement of women in scholarship and academic leadership. Right now this work is critically important in my field, as technology in machine learning, artificial intelligence, and computing changes our world on a daily basis. Technology is often thought of as an objective pursuit, where the goals are clear and well-defined, and only those who are “math geniuses” can make a contribution. This couldn’t be further from the truth – we are constantly defining the goals and values of our technology, and diverse voices are key to creating technology that lifts us up as a whole society.
November 5, 2024
IEEE Signal Processing Magazine – Special Issue on the Mathematics of Deep Learning
I am the lead guest editor on a Signal Processing Magazine special issue on the Mathematics of Deep Learning: https://signalprocessingsociety.org/publications-resources/special-issue-deadlines/ieee-spm-special-issue-mathematics-deep-learning. My excellent co-editors are Joan Bruna, Gitta Kutyniok, Robert Nowak, and Jong Chul Ye. We have extended the White Paper deadline to this Friday, November 8. Please share with anyone who is interested but missed the deadline last Friday. We look forward to your submissions!
June 25, 2024
Code for Deep LoRA
Our ICML paper “Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation” shows that it is possible to get the benefits of deep overparameterization without increasing the number of trainable parameters. The code for our experiments can be found at Can’s github site: https://github.com/cjyaras/deep-lora-transformers. We welcome any thoughts and questions if you use and adapt our code for your problem!
June 25, 2024
SPADA lab at ICML in Vienna
I am excited to be a part of three papers at the International Conference of Machine Learning this July in Vienna.
Congratulations to Can Yaras for having his work on compression in deep low-rank learning, with co-authors Peng Wang and Qing Qu, accepted as an oral presentation for Tuesday afternoon! This work proves that when training deep linear networks, the gradient descent dynamics are limited to an invariant subspace. This subspace can be leveraged to make training and overparameterization more efficient, and allows us to reap the benefits of deep overparameterization without the computational burden. The code is available on Can’s github site. I talked about this work for the 1W-Minds seminar in April.
Peng Wang and Huikang Liu led our work on symmetric matrix completion with ReLU sampling that will be presented as a poster on Wednesday. We showed that it is possible to recover a low-rank matrix with sampling that is highly dependent on the matrix entries — we focus on ReLU sampling (and variants) where only positive entries are observed.
Finally, Wisconsin-Madison PhD student Yuchen Li will be presenting his work on block Riemannian MM methods, also with a poster on Wednesday. He proved iteration guarantees for convergence to a stationary point for general multi-block MM algorithms where any number of blocks may be constrained to a Riemannian manifold. His complexity results reduce to well-known results in the Euclidean case. This work is broadly applicable to alternating MM algorithms for machine learning problems.