The attention module in transformer architectures is often the most computation and memory intensive unit. Many researchers have tried different ways to approximate softmax attention in a compute efficient way. We have a new approach that uses the Monarch matrix structure along with variational softmax to quickly and accurately approximate softmax attention in a zero-shot setting. The results are very exciting — we can significantly decrease the compute and memory requirements while taking at most a small hit to performance. This figure shows the performance versus computation of our “Monarch-Attention” method as compared to Flash Attention 2 (listed as “softmax”) and other fast approximations.
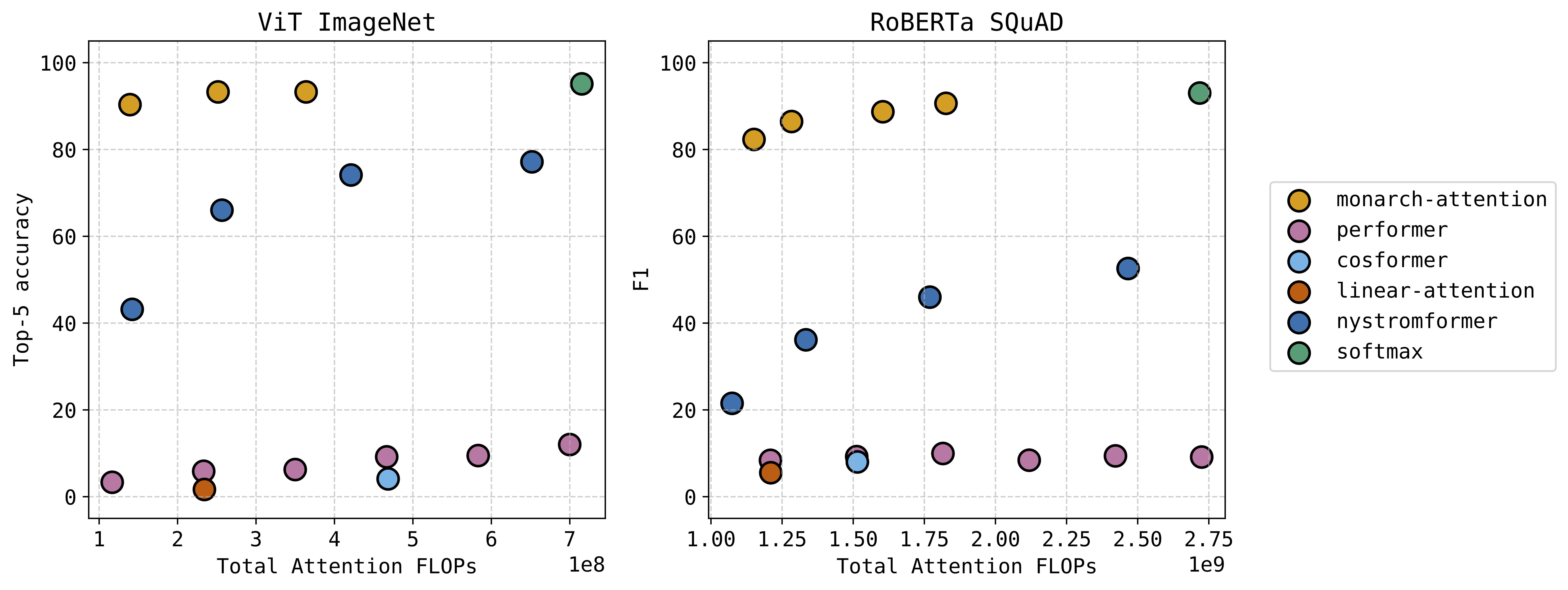
See the paper for additional results, including hardware benchmarking against Flash Attention 2 on several sequence lengths.
Can Yaras, Alec S. Xu, Pierre Abillama, Changwoo Lee, Laura Balzano. “MonarchAttention: Zero-Shot Conversion to Fast, Hardware-Aware Structured Attention.”
https://arxiv.org/abs/2505.18698
Code can be found here.