Laura Balzano
Office: EECS 4230C
1301 Beal Ave, Ann Arbor, MI 48109
Phone: (734) 615-9451
Recent News
Signal Processing Magazine special issue on the Mathematics of Deep Learning
I am excited to say that our SPM special issue, part 1, on the Mathematics of Deep Learning, has now been published in ieee explore.
As we said in our guest editorial, “The aim of this special issue is to capture some of the salient points of contact between the SP and DL disciplines so that a mathematical picture of the key questions and challenges ahead begins to emerge.” The eight papers in this part of the issue all display these contact points beautifully: from sparsity to Kalman filtering to probability.
SPM is a venue that provides tutorial-like material on important signal processing topics. I hope you will read the issue and share the material with your junior graduate students.
SPADA lab at Neurips 2025
SPADA lab had two interesting works to share at Neurips this year. The first was MonarchAttention, which received a spotlight; thanks to everyone who stopped by the poster. See our earlier post for an example of how our method offers a zero-shot drop-in replacement for softmax attention at a significant savings of memory and computation – with very little accuracy loss. This technique has a University of Michigan patent pending.
The second work is on the topic of Out-of-Distribution In-Context Learning, which we presented at the What Can’t Transformers Do? Workshop. We analyze the solution for training linear attention on an out-of-distribution linear regression test task, where the training task is a regression vector either drawn from a single subspace or a union of subspaces. In the case of a union of subspaces, we can generalize to the span of the subspaces at test time.
Nice work to all the students: Can, Soo Min (both SPADA lab members), as well as our treasured collaborators Alec, Pierre, and Changwoo!
Monarch Attention
The attention module in transformer architectures is often the most computation and memory intensive unit. Many researchers have tried different ways to approximate softmax attention in a compute efficient way. We have a new approach that uses the Monarch matrix structure along with variational softmax to quickly and accurately approximate softmax attention in a zero-shot setting. The results are very exciting — we can significantly decrease the compute and memory requirements while taking at most a small hit to performance. This figure shows the performance versus computation of our “Monarch-Attention” method as compared to Flash Attention 2 (listed as “softmax”) and other fast approximations.
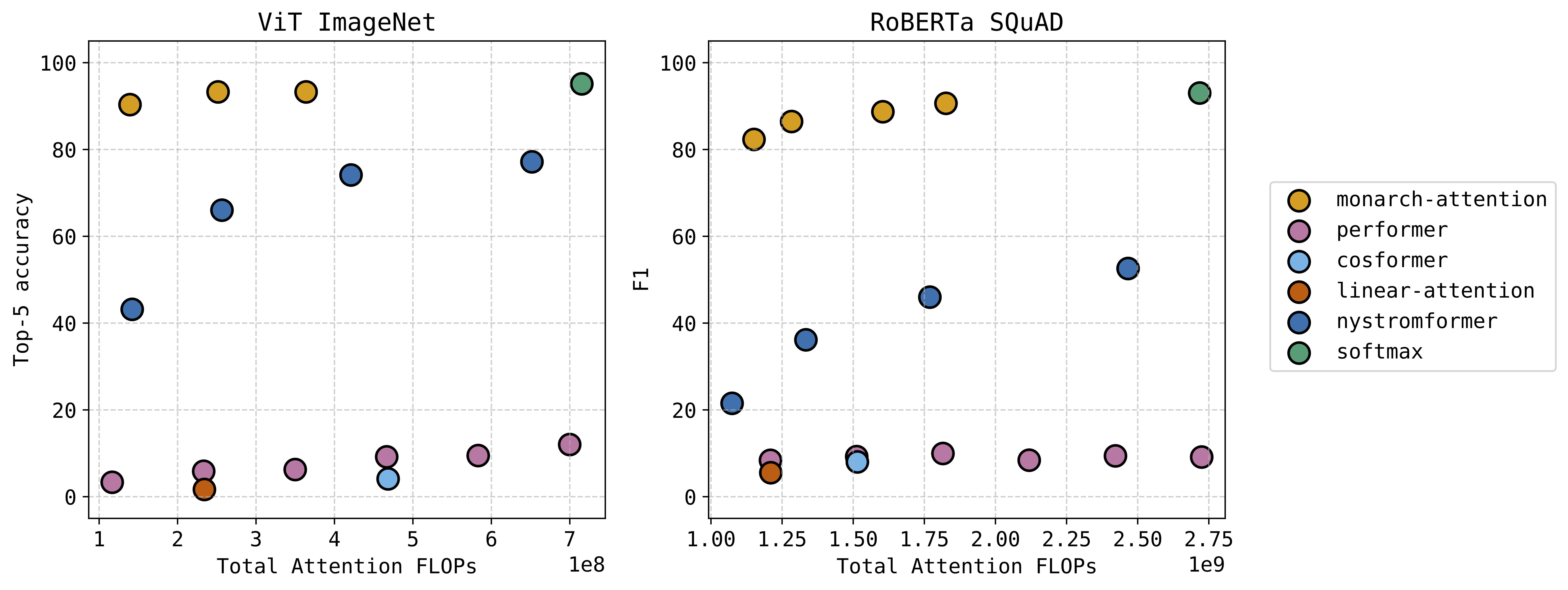
See the paper for additional results, including hardware benchmarking against Flash Attention 2 on several sequence lengths.
Can Yaras, Alec S. Xu, Pierre Abillama, Changwoo Lee, Laura Balzano. “MonarchAttention: Zero-Shot Conversion to Fast, Hardware-Aware Structured Attention.”
https://arxiv.org/abs/2505.18698
Code can be found here.