
Jason J. Corso
| Snippets by Topic | |
| * | Active Clustering |
| * | Activity Recognition |
| * | Medical Imaging |
| * | Metric Learning |
| * | Semantic Segmentation |
| * | Video Segmentation |
| * | Video Understanding |
| Selected Project Pages | |
| * | Action Bank |
| * | LIBSVX: Supervoxel Library and Evaluation |
| * | Brain Tumor Segmentation |
| * | CAREER: Generalized Image Understanding |
| * | Summer of Code 2010: The Visual Noun |
| * | ACE: Active Clustering |
| * | ISTARE: Intelligent Spatiotemporal Activity Reasoning Engine |
| * | GBS: Guidance by Semantics |
| * | Semantic Video Summarization |
| Data Sets | |
| * | A2D: Actor-Action Dataset |
| * | YouCook |
| * | Chen Xiph.org |
| * | UB/College Park Building Facades |
| Other Information | |
| * | Code/Data Downloads |
| * | List of Grants |
People: Jason Corso (PI), Raymond Fu, Werner Ceusters, Venkat Krovi, and Michalis Petropoulos
Funding Agency: DARPA Mind's Eye in TCTO. This project kicked off in June 2010.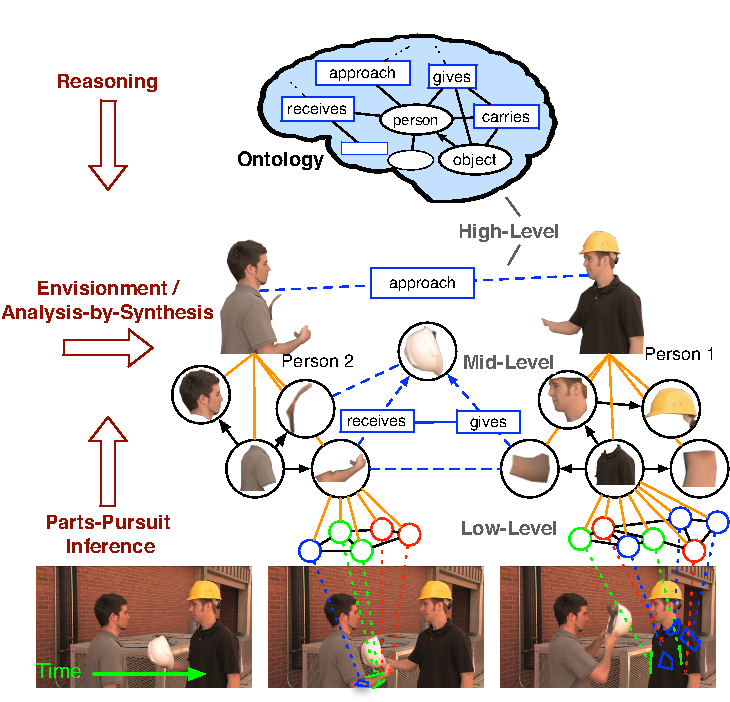
Funding Agency: DARPA Mind's Eye in TCTO. This project kicked off in June 2010.
Capabilities and Demonstration Video of Current System
Overview and Project Goals
Comprehensive visual scene understanding has long been the ultimate challenge
in computer vision research. While images and videos of the natural world are
highly structured and redundant (Kersten, 1987; Ruderman, 1994), they exhibit
complex appearance and shape, complex hierarchical scale-varying nature, and
occlusion. Early successes have focused on particular sub-problems, such as
face detection (Viola and Jones, 2002, 2004). State of the art systems are
capable of detecting instances of objects-the "nouns" of the scene-among few
hundreds of object classes (Fei-Fei et al., 2004) and contests such as the
PASCAL Challenge annually pit the world's best object detection methods on
novel datasets. Although some may argue these object detection methods have not
been thoroughly evaluated in the wild, a more elusive problem now presents
itself: the "verbs" of the scene. As Biederman stated, nearly 30 years ago,
specifying not only the elements in an image but also the manner in which they
are interacting and relating to one another is integral to full image
understanding (Biederman, 1981).
However, representing and recognizing actions (especially those of
humans), with a view to understanding their underlying motivation, has proved
to be an extremely challenging task because: (A) Motion is the projected output
of a set of coordinated actions of often high-dimensional systems, an extremely
high-dimensional neuro-musculo-skeletal one in the case of humans (and thus not
particularly well-suited for any attempt at reconstruction solely on the basis
of visual observation of coordinated actions); (B) Motion occurs and gets
described semantically/linguistically at a wide variety of spatiotemporal
scales (i.e. varying levels of abstraction serve to agglomerate or subdivide
either spatial- and temporal-characteristics and careful attention paid to
appropriate creation of "equivalence classes"); (C) Most importantly, the
unambiguous extraction of intent from motion alone can never be achieved due to
the significant dependence upon contextual knowledge (making the case for the
development of a systematic ontology in which to ground the visual reasoning).
This representation, learning, recognition of and reasoning over activities in
persistent surveillance videos is the overarching objective of ISTARE
Data / Code Releases:
- May 11 Annotation of human keypoints, human segmentations, and related processing. This set includes all videos used in the ARL Feb '11 roundtable set (52 videos) fully annotated. [Download]
- August 11 Annotation of verb times on C-D1 (2740 of the 3492 remaining ones being added). This set includes time labels for each of the verb's identified in the C-D1 videos (using the DARPA HR data). [Download]
Please acknowledge any use of these releases
Other Info:
- The Summer of Code 2010 The Visual Noun is closely related to the ISTARE effort and will help define the foundation on which the new research will build.
Publications:
| [1] | C. Chen and J. J. Corso. Joint occlusion boundary detection and figure/ground assignment by extracting common-fate fragments in a back-projection scheme. Pattern Recognition, 64:15--28, 2017. [ bib ] |
| [2] | D. M. Johnson, C. Xiong, and J. J. Corso. Semi-supervised nonlinear distance metric learning via forests of max-margin cluster hierarchies. IEEE Transactions on Knowledge and Data Engineering, 28(4):1035--1046, 2016. [ bib | DOI | .pdf ] |
| [3] | C. Xu and J. J. Corso. LIBSVX: A supervoxel library and benchmark for early video processing. International Journal of Computer Vision, 119:272--290, 2016. [ bib ] |
| [4] | R. Xu, C. Xiong, W. Chen, and J. J. Corso. Jointly modeling deep video and compositional text to bridge vision and language in a unified framework. In Proceedings of AAAI Conference on Artificial Intelligence, 2015. [ bib | .pdf ] |
| [5] | P. Agarwal, S. Kumar, J. Ryde, J. J. Corso, and V. N. Krovi. Estimating dynamics on-the-fly using monocular video for vision-based robotics. IEEE/ASME Transactions on Mechatronics, 19(4):1412--1423, 2014. [ bib | http ] |
| [6] | C. Xu, R. F. Doell, S. J. Hanson, C. Hanson, and J. J Corso. A study of actor and action semantic retention in video supervoxel segmentation. International Journal of Semantic Computing, 2014. Selected as a Best Paper from ICSC; an earlier version appeared as arXiv:1311.3318. [ bib | .pdf ] |
| [7] | W. Chen, C. Xiong, R. Xu, and J. J. Corso. Actionness ranking with lattice conditional ordinal random fields. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2014. [ bib | poster | code | .pdf ] |
| [8] | A. Barbu, D. Barrett, W. Chen, N. Siddharth, C. Xiong, J. J. Corso, C. D. Fellbaum, C. Hanson, S. J. Hanson, S. Hélie, E. Malaia, B. A. Pearlmutter, J. M. Siskind, T. M. Talavage, and R. B. Wilbur. Seeing is worse than believing: Reading people's minds better than computer-vision methods recognize actions. In Proceedings of European Conference on Computer Vision, 2014. [ bib | .pdf ] |
| [9] | J. J. Corso. Toward parts-based scene understanding with pixel-support parts-sparse pictorial structures. Pattern Recognition Letters: Special Issue on Scene Understanding and Behavior Analysis, 34(7):762--769, 2013. Early version appears as arXiv.org tech report 1108.4079v1. [ bib | .pdf ] |
| [10] | Y. Miao and J. J. Corso. Hamiltonian streamline guided feature extraction with application to face detection. Journal of Neurocomputing, 120:226--234, 2013. Early version appears as arXiv.org tech report 1108.3525v1. [ bib | http ] |
| [11] | P. Das, C. Xu, R. F. Doell, and J. J. Corso. A thousand frames in just a few words: Lingual description of videos through latent topics and sparse object stitching. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2013. [ bib | poster | data | .pdf ] |
| [12] | C. Xu, R. F. Doell, S. J. Hanson, C. Hanson, and J. J Corso. Are actor and action semantics retained in video supervoxel segmentation? In Proceedings of IEEE International Conference on Semantic Computing, 2013. [ bib | .pdf ] |
| [13] | C. Xu, S. Whitt, and J. J. Corso. Flattening supervoxel hierarchies by the uniform entropy slice. In Proceedings of the IEEE International Conference on Computer Vision, 2013. [ bib | poster | project | video | .pdf ] |
| [14] | J. A. Delmerico, P. David, and J. J. Corso. Building facade detection, segmentation, and parameter estimation for mobile robot stereo vision. Image and Vision Computing, 31(11):841--852, 2013. [ bib | project | data | .pdf ] |
| [15] | A. Barbu, N. Siddharth, C. Xiong, J. J. Corso, C. D. Fellbaum, C. Hanson, S. J. Hanson, S. Hélie, E. Malaia, B. A. Pearlmutter, J. M. Siskind, T. M. Talavage, and R. B. Wilbur. The compositional natural of verb and argument representations in the human brain. Technical Report 1306.2293, arXiv, 2013. [ bib | http ] |
| [16] | C. Xu and J. J. Corso. Evaluation of super-voxel methods for early video processing. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2012. [ bib | code | project | .pdf ] |
| [17] | S. Sadanand and J. J. Corso. Action bank: A high-level representation of activity in video. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2012. [ bib | code | project | .pdf ] |
| [18] | P. Agarwal, S. Kumar, J. Ryde, J. J. Corso, and V. N. Krovi. Estimating human dynamics on-the-fly using monocular video for pose estimation. In Proceedings of Robotics Science and Systems, 2012. [ bib | .pdf ] |
| [19] | R. Xu, P. Agarwal, S. Kumar, V. N. Krovi, and J. J. Corso. Combining skeletal pose with local motion for human activity recognition. In Proceedings of VII Conference on Articulated Motion and Deformable Objects, 2012. [ bib | slides | .pdf ] |
| [20] | P. Agarwal, S. Kumar, J. Ryde, J. J. Corso, and V. N. Krovi. An optimization based framework for human pose estimation in monocular videos. In Proceedings of International Symposium on Visual Computing, 2012. [ bib | .pdf ] |
| [21] | C. Xiong and J. J. Corso. Coaction discovery: Segmentation of common actions across multiple videos. In Proceedings of Multimedia Data Mining Workshop in Conjunction with the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (MDMKDD), 2012. [ bib | .pdf ] |
| [22] | C. Xu, C. Xiong, and J. J. Corso. Streaming hierarchical video segmentation. In Proceedings of European Conference on Computer Vision, 2012. [ bib | code | project | .pdf ] |
| [23] | Y. Miao and J. J. Corso. Hamiltonian streamline guided feature extraction with applications to face detection. Technical Report 1108.3525v1, arXiv, August 2011. [ bib ] |
| [24] | P. Agarwal, S. Kumar, J. J. Corso, and V. N. Krovi. Estimating dynamics on-the-fly using monocular video. In Proceedings of 4th Annual Dynamic Systems and Control Conference, 2011. [ bib | .pdf ] |
| [25] | J. A. Delmerico, P. David, and J. J. Corso. Building facade detection, segmentation, and parameter estimation for mobile robot localization and guidance. In Proceedings of International Conference on Intelligent Robots and Systems, 2011. [ bib | project | data | .pdf ] |
| [26] | W. Ceusters, J. J. Corso, Y. Fu, M. Petropoulos, and V. Krovi. Introducing ontological realism for semi-supervised detection and annotation of operationally significant activity in surveillance videos. In Proceedings of the 5th International Conference on Semantic Technologies for Intelligence, Defense and Security (STIDS), 2010. [ bib | .pdf ] |
| [27] | A. Y. C. Chen and J. J. Corso. Propagating multi-class pixel labels throughout video frames. In Proceedings of Western New York Image Processing Workshop, 2010. [ bib | .pdf ] |