I have co-founded Keebo!
Keebo is a turn-key Data Learning technology, which automates and accelerates enterprise analytics. You can learn more here.

I build data-intensive systems that are more scalable, more robust, and more predictable. I draw from advanced statistical models to deliver practical database solutions to real-world problems. In particular, I adapt concepts and tools from applied statistics, optimization theory, and machine learning.
Barzan Mozafari is an Associate Professor of Computer Science and Engineering at the University of Michigan, Ann Arbor, where he leads a research group designing the next generation of scalable databases using advanced statistical models. Prior to that, he was a Postdoctoral Associate at MIT. He earned his Ph.D. in Computer Science from UCLA in 2011. His research career has led to several open-source projects, including BlinkDB (the first massively parallel approximate query engine), DBSeer (the first automated database diagnosis tool), and VerdictDB (the first platform-independent approximate query engine). He helped commercialize the ideas introduced by BlinkDB, as part of SnappyData, a company that was later acquired by TIBCO. He has won the National Science Foundation CAREER award, as well as several best paper awards in ACM SIGMOD and EuroSys.
about projects publications vita students press coverage
exciting news
SnappyData acquired by TIBCO!
As of March 2019, SnappyData is officially part of
TIBCO Software Inc.
Here's the vision paper we wrote two years ago at CIDR 2017!
I am organizing the first ACAIA workshop, a workshop on
Approximate Computing for Affordable and Interactive Analytics.
ACAIA 2017 aims to bridge the gap between academia and industry by discussing the latest advances in
approximate computing. You can register here.

SIGMOD Jim Gray Dissertation Award Runner-up:
My student (co-advised by Micheal Cafarella), Yongjoo Park is the runner-up winner of this year's SIGMOD Jim Gray Dissertation Award
for his work on "Fast Data Analytics by Learning". Congratulations to Yongjoo!

MySQL, the most popular DB in the world, adopts our CATS algorithm as its the default scheduling strategy!
Our scheduling algorithm, known as Contention-Aware Transaction Scheduling (CATS), is now the default policy in Oracle MySQL too!
With this adoption, over 2M+ servers in the world are running CATS!
Congratulations to my students, Jiamin Huang and Boyu Tian, for developing these algorithms!
Read our papers in SIGMOD 2017, EuroSys 2017 and
VLDB 2018.

Our VATS algorithm is now the default scheduling strategy in MariaDB!
Starting MariaDB 10.2.3+, the default scheduling algorithm is Variance-Aware Transaction Scheduling (VATS),
an algorithm developed by my brilliant student Jiamin Huang and published in ACM SIGMOD 2017.

Morris Wellman Faculty Development Assistant Professorship
Humbled and honored to be named
Morris Wellman Faculty Development Assistant Professor. Many thanks to Wellman family for their generosity.
SnappyData v0.1 open sourced and available for Download!
SnappyData is a commercialization of approximate query processing, providing an integrated
framework for interactive analytics, transactions and stream processing. Check out our release!

$3.46M to combine supercomputer simulations with big data:
NSF and University of Michigan have jointly sponsored our ConFlux project: a massively parallel system for solving open problems in computational physics using large-scale machine learning!
CAREER Award: Designing a Predictable Database - An Overlooked Virtue
Database research has mostly focused on improving the raw performance of database systems, while neglecting the predictability of their performance.
NSF has funded us to
rethink this traditional architecture, and build a new class of databases that guarantee predictability.
Vehicle-aware data management for autonomous cars
Testing autonomous vehicles is an extremely involved task, as an enormous amount of data is constantly collected and processed by thousands of sensors.
NSF has funded us to design a smart black-box for cars that can use effective data collection strategies for maximizing the likelihood of finding various types of faults!

Big Data Summer Institute in Bio-statistics
Funded by National Institutes of Health, we have launched our Big Data Summer Institute, where you can learn about Big Data, statistics and bio-informatics while getting paid!
All details and how to apply, can be found here (do NOT email me about this)!
SIGMOD's Best Demo Award:
Our ABS system won this year's best demo award at SIGMOD!
We also had a number of papers on Approximate Query Processing at this year's SIGMOD (2014).
|
selected projects
VerdictDB Approximation for All.
Video: Watch a live demo Software: Download VerdictDB for Amazon Redshift, Apache Hive, Apache Spark, and Impala Papers: SIGMOD'17, Press: UM News, 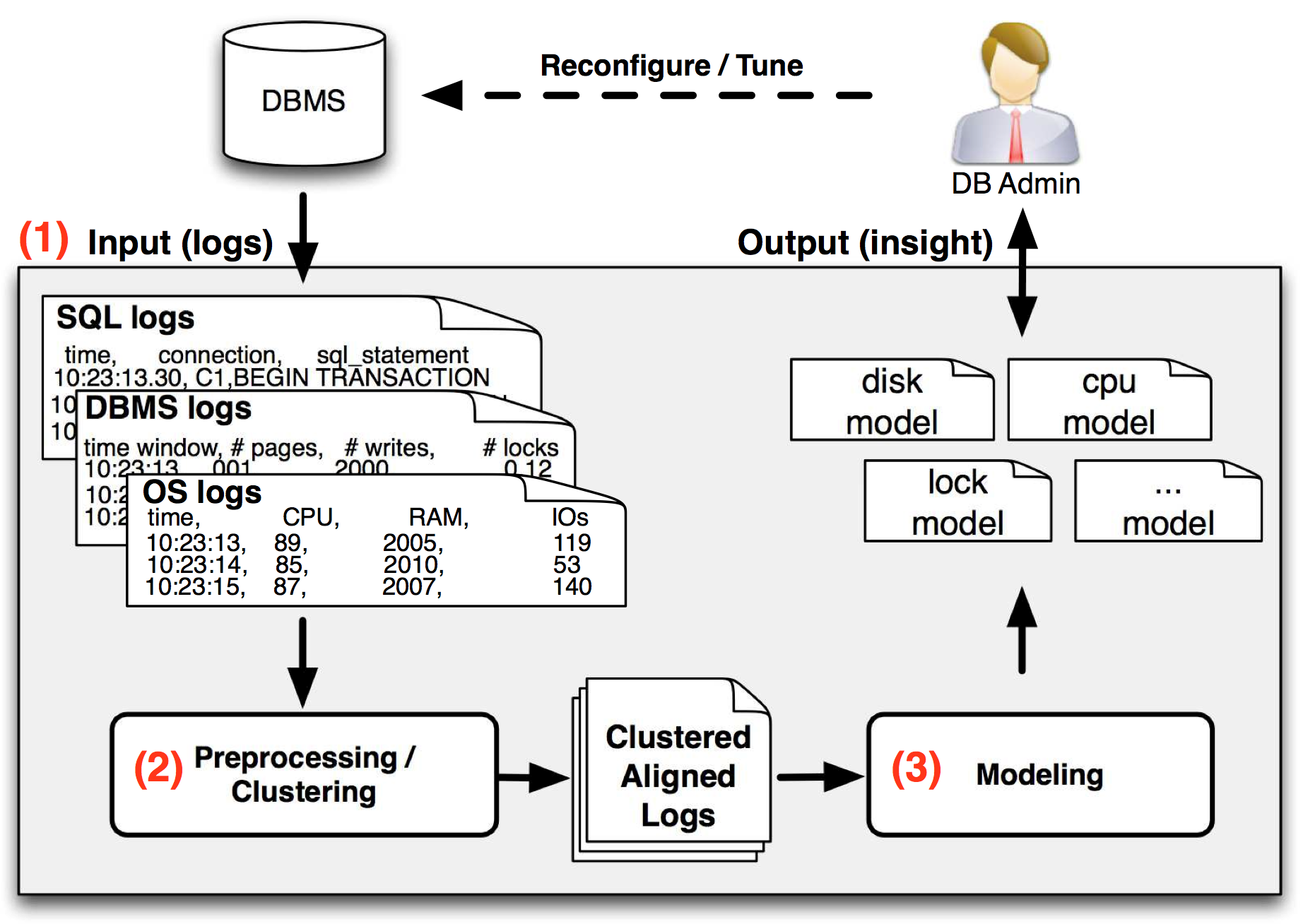
DBSeer: Self-Driving Databases automatic resource provisioning, automatic performance diagnosis, and automatic physical design.
Video: Watch a live demo Software: DBSeer for MySQL & PostgreSQL Papers: CIDR'13, SIGMOD'13, PVLDB'15 (demo) Press: Wall Street Journal (CIO), MIT News, The Register, R&D Magazine, ... 
BlinkDB Delivering sub-second latency when querying terabytes and petabytes of data.
Software: BlinkDB (for Hive/Shark) Papers: PVLDB'12, EuroSys'13 (best paper award), SIGMOD'14 (1), SIGMOD'14 (2), SIGMOD'14 (demo), CIDR'15 Press: O'REILLY Strata, Telruptive, Innovation @ HP Labs 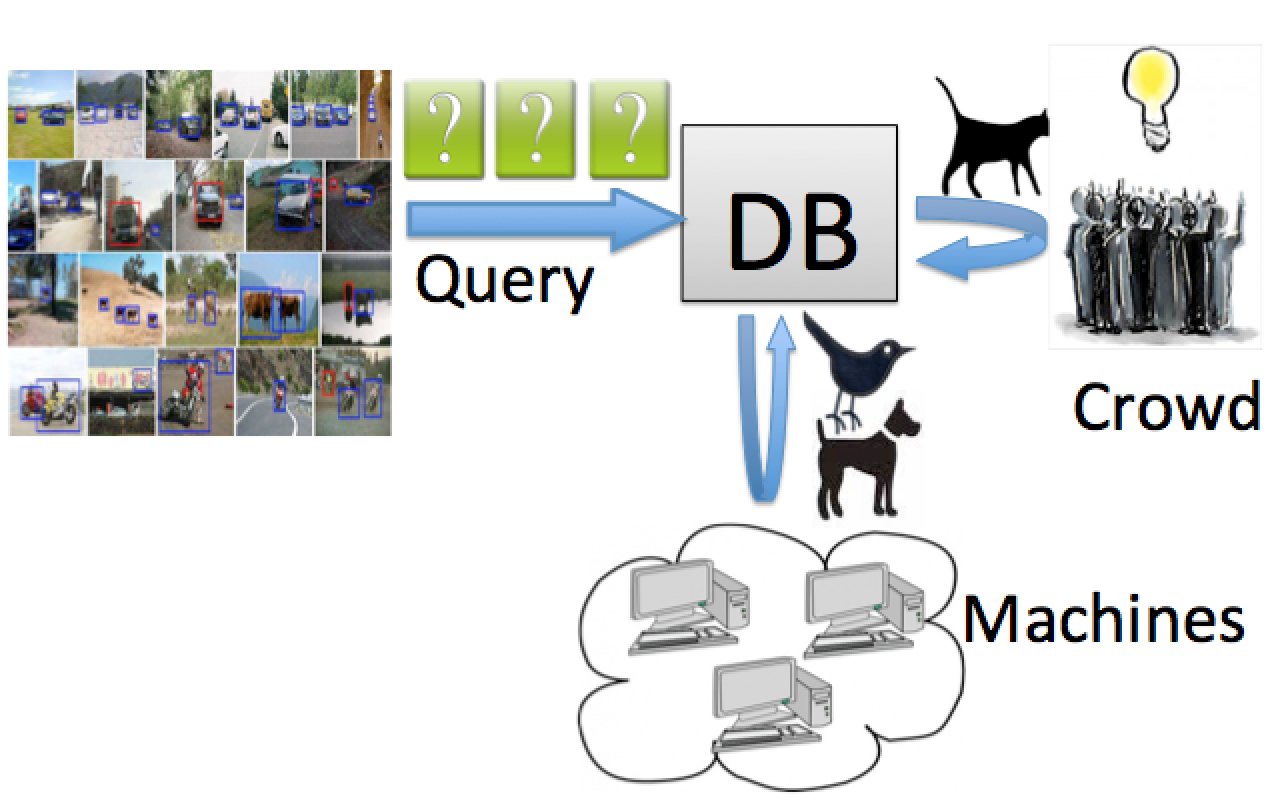
|

Associate Professor
Computer Science and Engineering
University of Michigan (Ann Arbor)
Database Group
Computer Science and Engineering
4769 Beyster Building
2260 Hayward St.
University of Michigan
Ann Arbor, MI 48109-2121
Phone: (734) 763-3669
Email: mozafari@umich.edu
 : @BarzanMozafari
: @BarzanMozafari
Office hours: by appointment only
Curriculum vitae · all publications
Archived faculty app: research, teaching
Talks & Travel
| Jun 25 | SIGMOD |
| Nov 21 | Google Kirkland |
| Nov 22 | University of Washington |
| May 30 | Teradata (San Diego) |
| May 31 | UCLA |
| June 23-26 | SIGMOD |
| Jan 4-7 | CIDR |
Teaching
Fall 2020
EECS 484: Database Management Systems
Fall 2018
EECS 584: Advanced Database Management Systems
Fall 2015
EECS 584: Advanced Database Management Systems
Winter 2015
EECS 484: Database Management Systems
Fall 2014
EECS 584: Advanced Database Management Systems
Winter 2014
EECS 684: Current Topics in Databases
Acknowledgements
Our research is made possible through the generosity of the University of Michigan.
* This website's template is borrowed from Michael Bernstein and Jeffrey Heer.