|
Jason J. Corso
|
Snippet Topic: Semantic Segmentation
Joint Actor-Action Understanding  | Can humans fly? Emphatically no. Can cars eat? Again, absolutely not. Yet, these absurd inferences result from the current disregard for particular types of actors in action understanding. There is no work we know of on simultaneously inferring actors and actions in the video, not to mention a dataset to experiment with. Our CVPR 2015 paper formulates the general actor-action understanding problem and instantiate it at various granularities: both video-level single- and multiple-label actor-action recognition and pixel-level actor-action semantic segmentation. We work with a novel Actor-Action Dataset (A2D) comprised of 3782 videos of seven actor classes and eight action classes labeled at the pixel granularity, sparsely in time. The A2D dataset serves as a novel large-scale testbed for various vision problems: video-level single- and multiple-label actor-action recognition, instance-level object segmentation/co-segmentation, as well as pixel-level actor-action semantic segmentation to name a few. Our experiments demonstrate that inference jointly over actors and actions outperforms inference independently over them, and hence concludes our argument of the value of explicit consideration of various actors in comprehensive action understanding.
|
|
C. Xu, S.-H. Hsieh, C. Xiong, and J. J. Corso.
Can humans fly? Action understanding with multiple classes of
actors.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2015.
[ bib |
poster |
data |
.pdf ]
|
|
|
Parts-based Model of the Full Scene 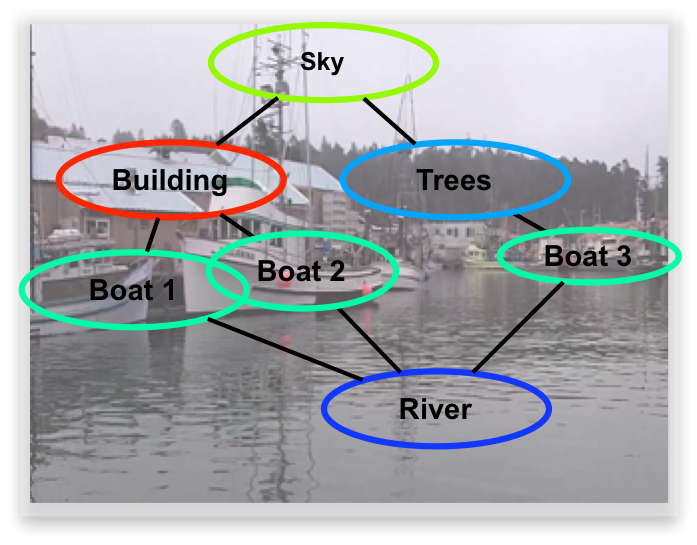 | Scene understanding remains a significant challenge in the computer vision community. The visual psychophysics literature has demonstrated the importance of interdependence among parts of the scene. Yet, the majority of methods in scene understanding remain local. Pictorial structures have arisen as a fundamental parts-based model for some vision problems, such as articulated object detection. However, the form of classical pictorial structures limits their applicability for global problems, such as semantic pixel labeling. In this work, we propose an extension of the pictorial structures approach, called pixel-support parts-sparse pictorial structures, or PS3, to overcome this limitation. Our model extends the classical form in two ways: first, it defines parts directly based on pixel-support rather than in a parametric form, and second, it specifies a space of plausible parts-based scene models and permits one to be used for inference on any given image. PS3 makes strides toward unifying object-level and pixel-level modeling of scene elements. We have thus far implemented the first half of our model and rely upon external knowledge to provide an initial graph structure for a given image.
|
|
J. J. Corso.
Toward parts-based scene understanding with pixel-support
parts-sparse pictorial structures.
Pattern Recognition Letters: Special Issue on Scene
Understanding and Behavior Analysis, 34(7):762--769, 2013.
Early version appears as arXiv.org tech report 1108.4079v1.
[ bib |
.pdf ]
|
More information about our earlier work in semantic region labeling is available here. |
|
Generalized Image Understanding 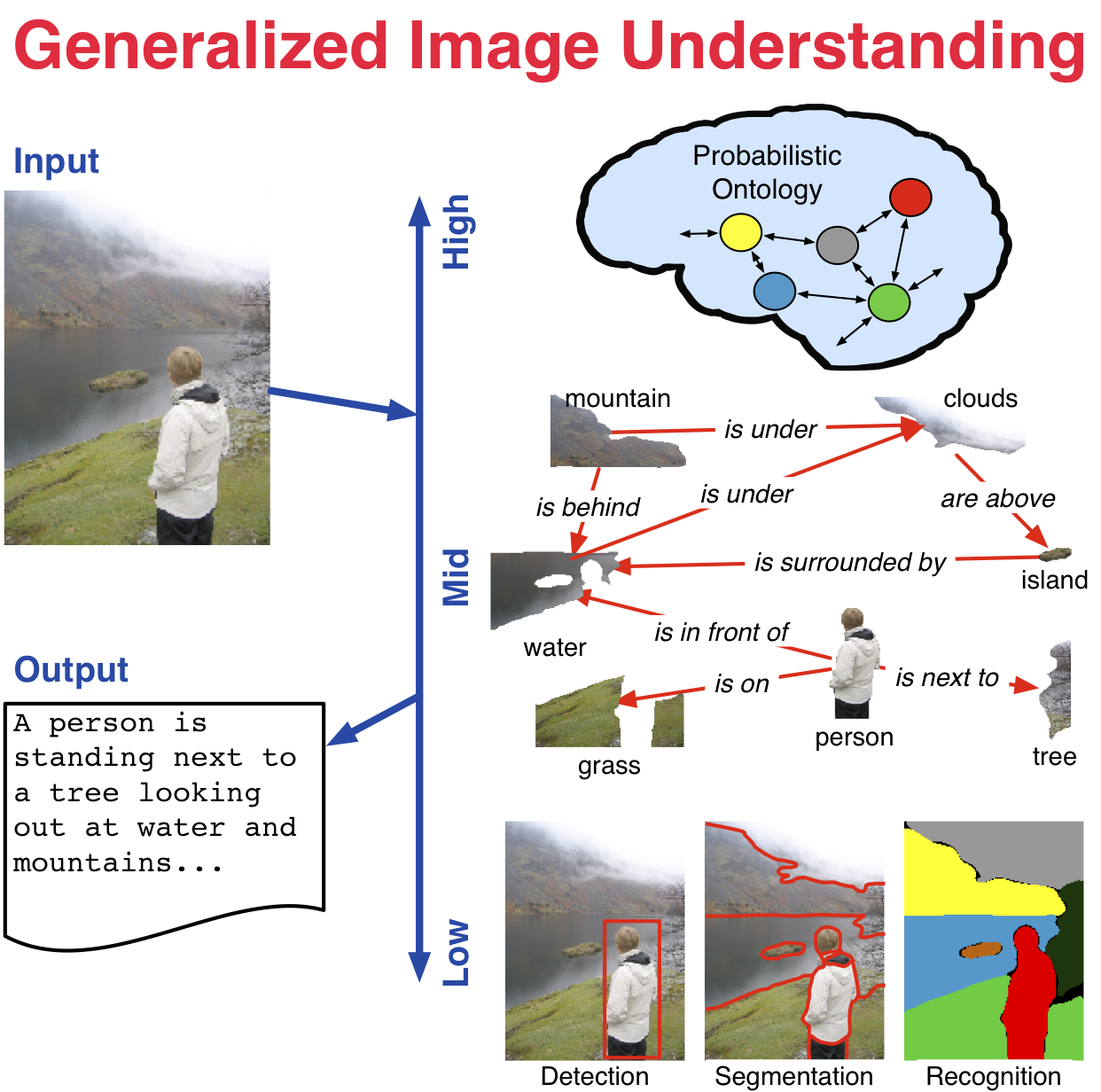 | NSF CAREER project is underway. From representation to learning to inference, effective use of high-level semantic knowledge in computer vision remains a challenge in bridging the signal-symbol gap. This research investigates the role of semantics in visual inference through the generalized image understanding problem: to automatically detect, localize, segment, and recognize the core high-level elements and how they interact in an image, and provide a parsimonious semantic description of the image. Specifically, this research examines a unified methodology that integrates low- (e.g., pixels and features), mid- (e.g. latent structure), and high-level (e.g., semantics) elements for visual inference. Adaptive graph hierarchies induced directly from the images provide the core mathematical representation. A statistical interpretation of affinities between neighboring pixels and regions in the image drives this induction. Latent elements and structure are captured with multilevel Markov networks. A probabilistic ontology represents the core knowledge and uncertainty of the inferred structure and guides the ultimate semantic interpretation of the image. At each level, rigorous methods from computer science and statistics are connected to and combined with formal semantic methods from philosophy. |
|
Graph-Shifts: Greedy Hierarchical Energy Minimization 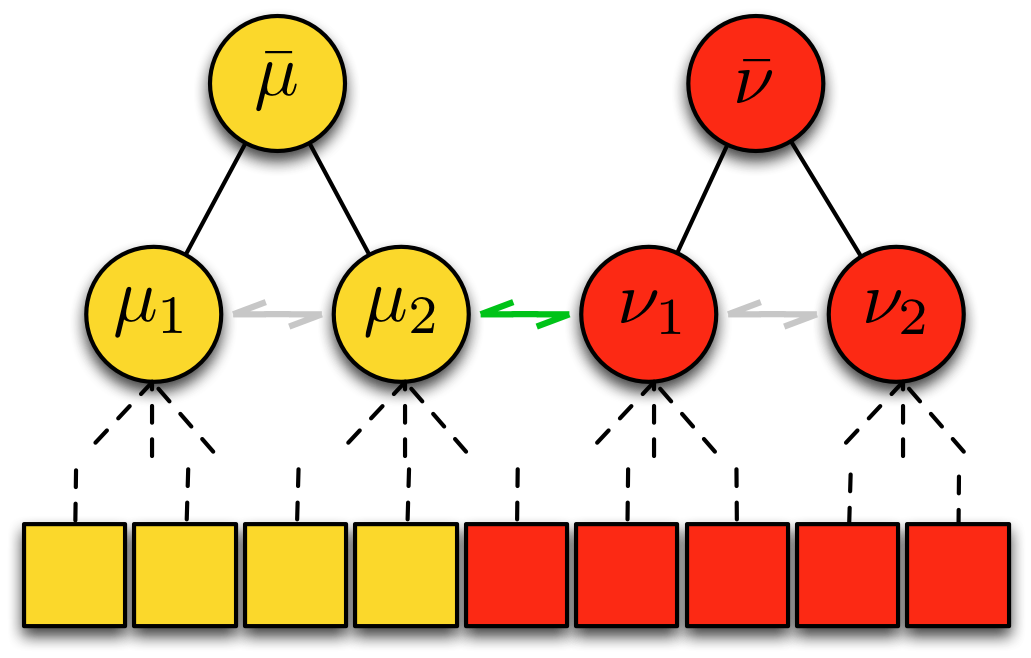 | Graph-Shifts is an energy minimization algorithm that manipulates a dynamic hierarchical decomposition of the data to rapidly and robustly minimize an energy function. It is a steepest descent minimizer that explores a non-local search space during minimization. A dynamic hierarchical representation makes exploration of this large search space plausible, and it facilitates both large jumps in the energy space analogous to combined split-and-merge operations as well as small jumps analogous to PDE-like moves. We use a deterministic approach to quickly choose the optimal move at each iteration. It has been applied in 2D and 3D joint image segmentation and classification in medical images, as depicted below for the segmentation of subcortical brain structures, and natural images as depicted at the semantic image labeling page. Graph-shifts typically converges orders of magnitude faster than conventional minimization algorithms, like PDE-based methods, and has been shown to be very robust to initialization.
|
|
J. J. Corso, A. Yuille, and Z. Tu.
Graph-Shifts: Natural Image Labeling by Dynamic Hierarchical
Computing.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2008.
[ bib |
code |
project |
.pdf ]
|
More information and code. |
|
Multilevel Segmentation with Bayesian Affinities  | Automatic segmentation is a difficult problem: it is under-constrained, precise physical models are generally not yet known, and the data presents high intra-class variance. In this research, we study methods for automatic segmentation of image data that strive to leverage the efficiency of bottom-up algorithms with the power of top-down models. The work takes one step toward unifying two state-of-the-art image segmentation approaches: graph affinity-based and generative model-based segmentation. Specifically, the main contribution of the work is a mathematical formulation for incorporating soft model assignments into the calculation of affinities, which are traditionally model free. This Bayesian model-aware affinity measurement has been integrated into the multilevel Segmentation by Weighted Aggregation algorithm. As a byproduct of the integrated Bayesian model classification, each node in the graph hierarchy is assigned a most likely model class according to a set of learned model classes. The technique has been applied to the task of detecting and segmenting brain tumor and edema, subcortical brain structures and multiple sclerosis lesions in multichannel magnetic resonance image volumes. More information. |
|
A Data Set for Video Label Propagation |
|

