| Award Number |
IIS 1054913 |
| Duration |
Five years |
| Award Title |
CAREER: Building and Searching a Structured Web Database |
| PI |
Michael Cafarella |
| Students |
Shirley Zhe Chen, Matthew Burgess, Jun Chen, Erdong Li, Shaobo Liu, Daniel Prevo, Guan Wang, Bochun Zhang, Junfeng Zhuang. |
| Collaborators |
Prof. Eytan Adar, for the work with scientific diagrams in year 1. Professors Margaret Levenstein, Matthew Shapiro, Christopher Re for the work on nowcasting in year 2 | .
| Project Goals |
Our initial research proposal focused on the following work for Year 2:
- Data Extraction: Start cost-based human supervision for judging extraction progress.
- Search System: Simple entity ranking results, using non-extracted datasets if needed.
- Broader Impacts: Initial search engine deployment. Initial release of extracted dataset.
As mentioned in last year’s report, the growth of high-quality structured online entity-centric datasets (such as Google’s Knowledge Graph) led us to change the focus of our work. We have been focusing on “somewhat structured” numeric datasets, such as data-driven diagrams and spreadsheet data. These datasets are still hard to obtain and enable most of our research program to continue.
Efforts B and C have taken place as described. Our deployed spreadsheet/database search system implements not just relevance ranking for text search; it also performs join-suggestion for deeper user queries. This extracted dataset is available for download.
Effort A has been retargeted to the problem of extracting relational data from elaborately structured objects such as spreadsheets. Instead of a cost-based system, this system is designed specifically to reduce manual human effort during the extraction review process. It uses a graphical structure that shares effort across many extractions in the spreadsheet corpus. This project is almost complete and is will be submitted for publication in the next 6 weeks.
In addition to the above efforts, we have used a small portion of these funds to start work on a form of “somewhat structured” data not present in the original proposal: short texts from services such as Twitter. Certain examples of such texts can be used for nowcasting applications where textual activity is used to characterize real-world phenomena. For example, if there is an increase in the quantity of people who mention, “I lost my job,” then the real-world unemployment rate may be going up. The nowcasting application area has received broad interest but academic analysis so far has been fairly minimal. Our work treats social media text as a form of “somewhat structured” data that varies over time instead of spatially like spreadsheets. Our work in this area has already yielded some good results, described below.
|
| Research Challenges |
The main thrust of work for the past year has been on extracting structured relations from spreadsheet data. There has also been a smaller amount of work in extracting time-varying information from Web-based social media text.
Spreadsheets are an important, but often overlooked, part of data management. They do not contain a huge volume of data as measured in sheer number of bytes, but are very important nonetheless. First, spreadsheets are the result of many human beings’ hard work and receive more direct attention than most other data: the information they contain was very expensive to obtain. Second, spreadsheets often hold data available nowhere else, so data systems must either process them or learn to live without.
Of course, any metadata in a spreadsheet is implicit, so they are unable to exploit the large number of tools designed for the relational model. In particular, integration among spreadsheets is a serious challenge. Spreadsheet software offers no easy way to combine information from multiple sources, even though organizations and some individuals now have spreadsheet collections that span decades.
Our system automatically transforms spreadsheets into their relational equivalent so they can be queried as if the data were simply contained in a traditional database. In case of errors, users can manually repair the extracted data.
Work for the past year focused on two areas:
- Enabling extraction of brittle metadata via effective manual repair. Many previous information extraction tasks have focused on populating a database that has already been designed; consider using a corpus of Web text to find pairs of company names and their headquarters locations. Recovering relational data from spreadsheets is quite different, because the spreadsheet includes the database design itself. Even small extraction errors when processing metadata can yield large numbers of errors in the output database. As a result, human beings must manually review and repair the automated extractor’s output, but doing so creates a large burden on the user.
- Improving the prototype structured search engine. A good structured data search engine must include not just effective ranking of search results, but also summarize search results via snippets, allow the user to exploit the structured search results via relational operators, and expose the manual repair features described above.
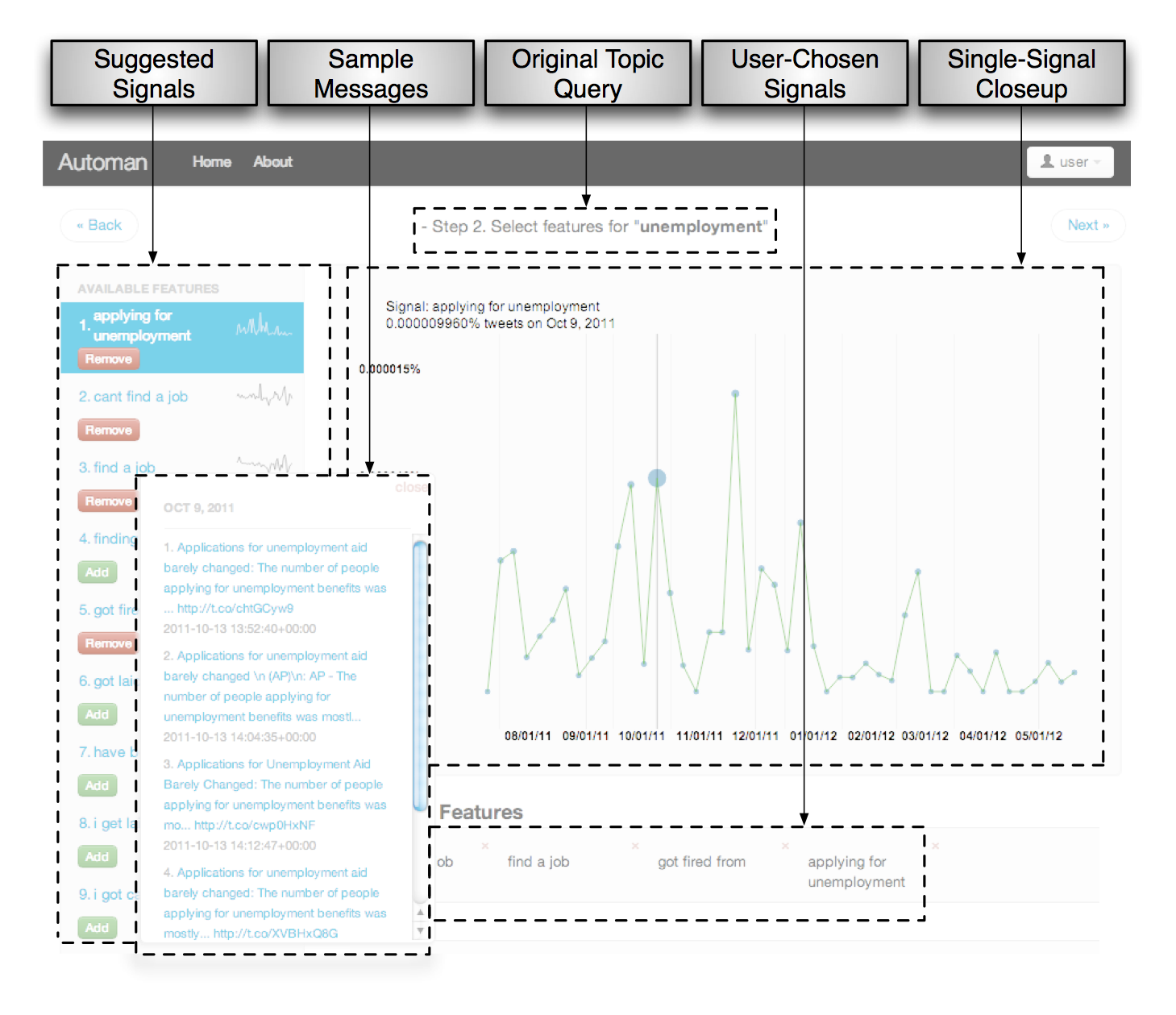
In addition to the spreadsheet work, a small amount of this grant was used to support investigation of time-varying structured texts such as Twitter streams, and their application to nowcasting applications. A particular problem in nowcasting is the choice of phrases that indicate a larger phenomenon. For example, repeated mentions of “I lost my job” may indicate a general rise in the unemployment rate. Given enough such signals (“I lost my job”, “I need a job”, etc) we can obtain time-varying signals from the social media source, then combine them into a prediction of the real-world unemployment rate.
Choosing such phrases may appear straightforward, but in fact humans are quite bad at choosing them; most suggestions from humans for a given phenomenon will be irrelevant. We would like to automate this procedure of choosing phrases for nowcasting. Traditional feature selection techniques would suggest using some known labeled data to evaluate candidate signals; in our case, we could rank all possible phrases by how well each correlates with the unemployment rate published by the US government.
Unfortunately, the set of potential phrases is so large (more than a billion), and the amount of traditional data so small (just tens of observations for most phenomena), that standard feature selection techniques overfit the available data and yield terrible results.
|
| Current results |
- Enabling extraction of brittle metadata via effective manual repair. We have built a spreadsheet extraction system that requires explicit manual review of all results. This review-and-repair stage is necessary because the metadata extraction associated with obtaining a novel relation is very brittle: even a single error can yield a database with many incorrect tuples. Thus, the system must provide 100% accuracy for most applications. As a result, the cost of a low-quality extractor is the amount of human labor it generates in the form of errors to be corrected.
For example, consider the metadata hierarchy below, recovered from a single column in a spreadsheet. The hierarchy to the left correctly finds that age categories like “18 to 24 years” are in fact refinements of “Male, total” and “White, total”. However, it does detect that “White, total” is itself a refinement of “Male, total”. Our system permits the user to improve the extracted output by dragging the “White, total” category to its correct location under “Male, total.”
Our extraction system obtains a good, though imperfect, initial extraction result for this kind of hierarchical metadata: it obtains an F1 score of between 81% and 92%, depending on the type of spreadsheet. This means a user must correct roughly 16 errors per spreadsheet, on average. Using the previous state-of-the-art, the user would have to correct almost 59 errors per spreadsheet, on average.
However, the real contribution of our system is in efficiently and repeatedly exploiting the user’s repairs. We use a conditional random field model to tie together multiple extraction decisions that are linked together either by similar style or by shared data. By finding extraction decisions that “should” be similar to each other, we can amortize the user’s repair over many errors simultaneously. As a result, we can reduce the total number of necessary repairs by as much as 65%.
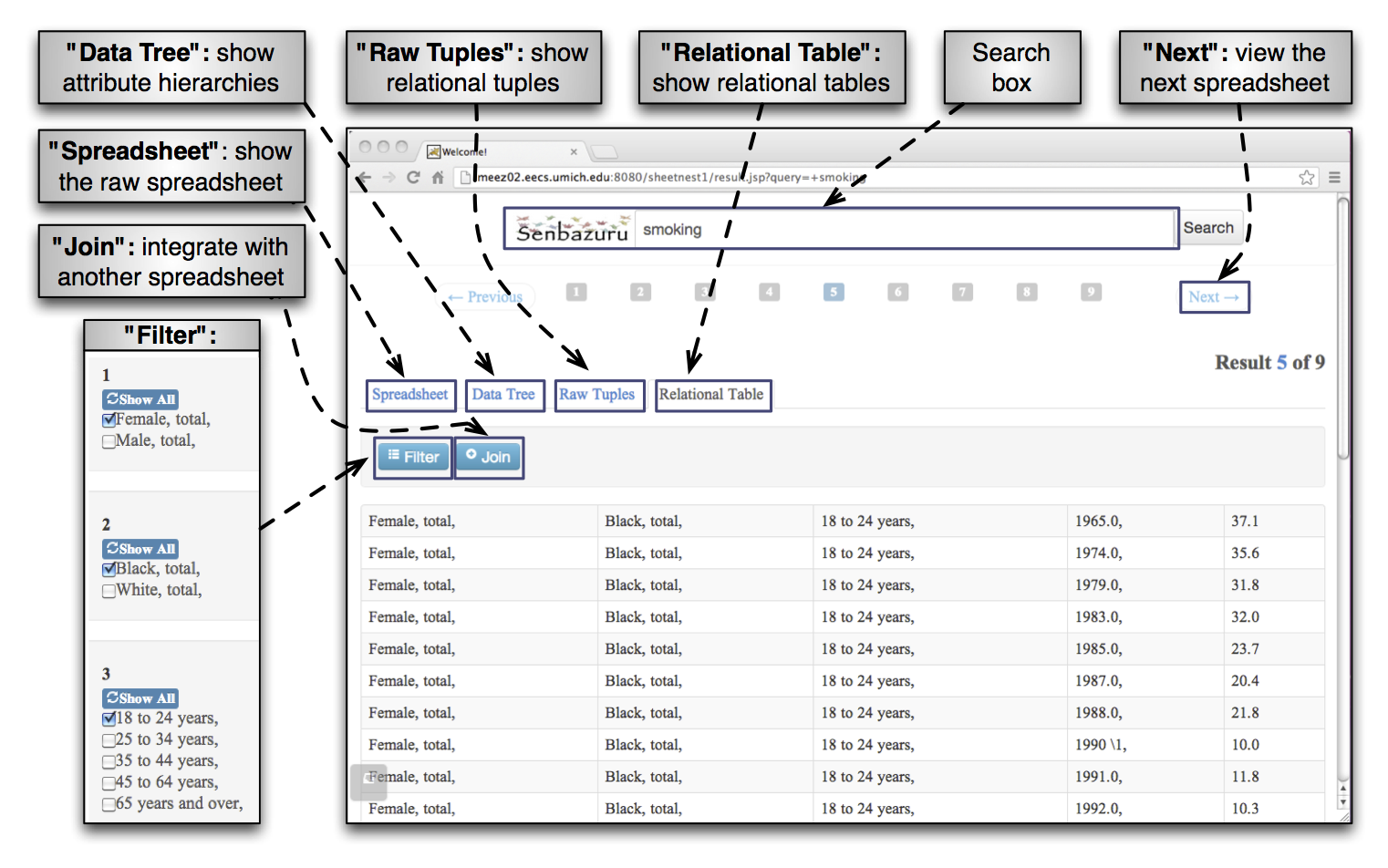
- A Structured Data Search Engine. We have applied the initial extractor to a large corpus of spreadsheets we obtained from the federal government’s Statistical Abstract of the United States, yielding roughly 1,700 novel databases on a range of topics. We then built a structured data search engine that enables access to this dataset.
It has a Web interface, which allows the user to enter a text query and obtain a list of results. The user can then examine the ranked set of search results, apply filters to a resulting table, and join a table to other spreadsheet-derived datasets. The user can also perform the extraction corrections described above.
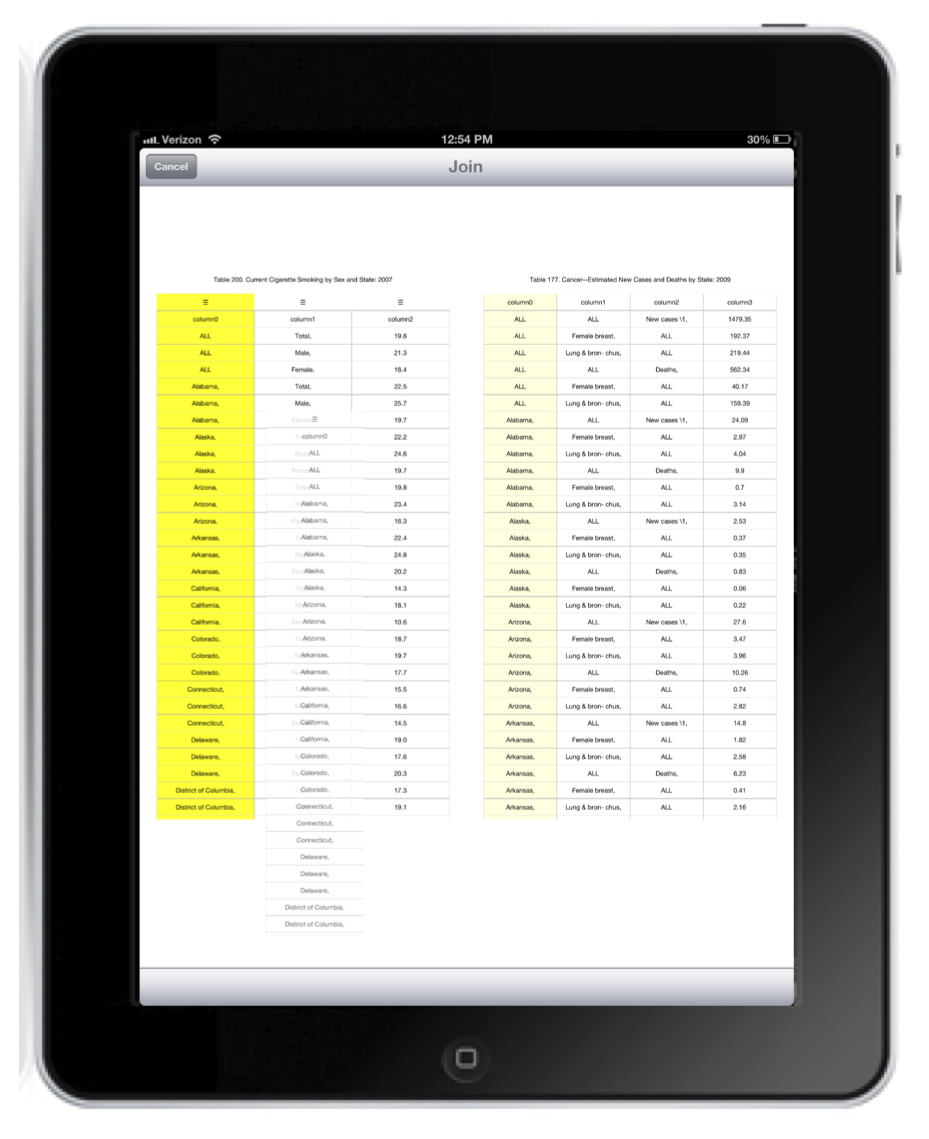
We have also built an iPad interface for the search engine. This interface has two advantages over the native Web-based one: the high-resolution display allows us to show more sample tuples, and expressing joins through touch-based gestures is much easier than in a traditional mouse-and-keyboard setting.
In the image shown below, the user has performed two text searches. The structured result of the first search is shown in the table to the left. The structured result of the second search is shown to the right. In this image, the user is in the process of expressing a join between the two by dragging a column from the left-hand side to the target column in the right-hand side.
This search engine has not yet been examined experimentally, but anecdotally has been a huge success among our test users.
Nowcasting. By avoiding use of the traditional dataset, and applying techniques that exploit statistics derived from the general Web corpus, we are able to build a useable synthetic feature selection mechanism. We tested it on six different social media phenomena, including unemployment, flu, retail sales, mortgage refinancing, and others. It can obtain results that are as good as, or in some cases slightly better than, those generated by a human being. We believe these results should help make nowcasting a real application rather than the strictly academic project it largely remains today.
|
| Publications |
- Zhe Chen, Michael Cafarella, Jun Chen, Daniel Prevo, Junfeng Zhuang: Senbazuru: A Prototype Spreadsheet Database Management System. VLDB Demo 2013.
- Dolan Antenucci, Erdong Li, Shaobo Liu, Michael J. Cafarella, Chistopher Ré: Ringtail: Nowcasting Made Easy. VLDB Demo 2013.
- Dolan Antenucci, Michael J. Cafarella, Margaret C. Levenstein, Christopher Ré, Matthew D. Shapiro: Ringtail: Feature Selection for Easier Nowcasting. WebDB 2013.
|
| Presentations |
- Managing Spreadsheets, keynote at New England Database Summit at MIT, February 2013
- Managing Spreadsheets, presented at Google, Palantir, Cloudera in May 2013
|
| Images/Videos |
|
| Data |
A lot of our work throws off datasets that are suitable for use by other researchers. Here is the data we have collected so far.
- Scientific Diagrams -- We obtained 300,000 diagrams from over 150,000 sources that we crawled online. Unfortunately, we believe we do not have the legal right to distribute the extracted diagrams themselves. (Live search engines are relatively free to summarize content as needed to present results.) However, you can download the URLs where we obtained diagrams here.
- Spreadsheet Extraction -- We have collected several spreadsheet corpora for testing the extraction system.
The first is the corpus of spreadsheets associated with the Statistical Abstract of the United States. As a series of US government publications, there are no copyright issues involved in redistributing it. You can download our crawled corpus of SAUS data here.
We have also crawled the Web to discover a large number of spreadsheets posted online. Unfortunately, copyright issues apply here, too. So here, too, we have assembled a downloadable list of the URLs where we found spreadsheets online. This should enable other researchers to find the resources we used and duplicate our results.
|
| Demos |
- Scientific Diagrams -- You can use our dedicated diagram search engine, DiagramFlyer, here.
- Spreadsheet Extraction -- You can use the prototype spreadsheet data search system, SheetsNest, here.
|
| Software downloads |
Our work so far involves fairly elaborate installations, so we have made the systems available for online use rather than download. |
| Patents |
None |
| Broader Impacts |
The PI discussed part of this work as part of a short class presented to high school students at Manchester High School in May, 2013. It had five components:
- PageRank and Search Engines
- Structured Databases and Social Networks
- Introduction to Data Mining
- Spreadsheet Extraction
- Time-Series Extraction from Social Media Sources
|
| Educational Material |
None yet |
| Highlights and Press |
Coverage of the MIT presentation here and here |
| Point of Contact |
Michael Cafarella |
| Last Updated |
June, 2013 |