Jason J. Corso
| Snippets by Topic | |
| * | Active Clustering |
| * | Activity Recognition |
| * | Medical Imaging |
| * | Metric Learning |
| * | Semantic Segmentation |
| * | Video Segmentation |
| * | Video Understanding |
| Selected Project Pages | |
| * | Action Bank |
| * | LIBSVX: Supervoxel Library and Evaluation |
| * | Brain Tumor Segmentation |
| * | CAREER: Generalized Image Understanding |
| * | Summer of Code 2010: The Visual Noun |
| * | ACE: Active Clustering |
| * | ISTARE: Intelligent Spatiotemporal Activity Reasoning Engine |
| * | GBS: Guidance by Semantics |
| * | Semantic Video Summarization |
| Data Sets | |
| * | YouCook |
| * | Chen Xiph.org |
| * | UB/College Park Building Facades |
| Other Information | |
| * | Code/Data Downloads |
| * | List of Grants |
Vision-Based Human-Machine Interaction
We have developed a methodology for vision-based interaction called
Visual Interaction Cues (VICs). The VICs paradigm is a methodology for
vision-based interaction operating on the fundamental premise that, in
general vision-based HCI settings, global user modeling and tracking are
not necessary. For example, when a person presses the number-keys while
making a telephone call, the telephone maintains no notion of the user.
Instead, it only recognizes the action of pressing a key. In contrast,
typical methods for vision-based HCI attempt to perform global user
tracking to model the interaction. In the telephone example, such
methods would require a precise tracker for the articulated motion of
the hand. However, such techniques are computationally expensive, prone
to error and the re-initialization problem, prohibit the inclusion of an
arbitrary number of users, and often require a complex gesture-language
the user must learn. In the VICs paradigm, we make the observation that
analyzing the local region around an interface component (the telephone
key, for example) will yield sufficient information to recognize user
actions.
Publications:
| [1] | D. R. Schlegel, A. Y. C. Chen, C. Xiong, J. A. Delmerico, and J. J. Corso. AirTouch: Interacting with computer systems at a distance. In Proceedings of IEEE Winter Vision Meetings: Workshop on Applications of Computer Vision (WACV), 2011. [ bib | .pdf ] |
| [2] | M. R. Malgireddy, J. J. Corso, S. Setlur, V. Govindaraju, and D. Mandalapu. A framework for hand gesture recognition and spotting using sub-gesture modeling. In Proceedings of the 20th International Conference on Pattern Recognition, 2010. [ bib | .pdf ] |
| [3] | J. J. Corso, G. Ye, D. Burschka, and G. D. Hager. A Practical Paradigm and Platform for Video-Based Human-Computer Interaction. IEEE Computer, 42(5):48-55, 2008. [ bib | .pdf ] |
| [4] | J. J. Corso. Techniques for Vision-Based Human-Computer Interaction. PhD thesis, The Johns Hopkins University, 2005. [ bib | .pdf ] |
| [5] | J. J. Corso, G. Ye, and G. D. Hager. Analysis of Composite Gestures with a Coherent Probabilistic Graphical Model. Virtual Reality, 8(4):242-252, 2005. [ bib | .pdf ] |
| [6] | D. Burschka, G. Ye, J. J. Corso, and G. D. Hager. A Practical Approach for Integrating Vision-Based Methods into Interactive 2D/3D Applicationsa. Technical report, The Johns Hopkins University, 2005. CIRL Lab Technical Report CIRL-TR-05-01. [ bib | .pdf ] |
| [7] | G. Ye, J. J. Corso, and G. D. Hager. Real-Time Vision for Human-Computer Interaction, chapter 7: Visual Modeling of Dynamic Gestures Using 3D Appearance and Motion Features, pages 103-120. Springer-Verlag, 2005. [ bib | .pdf ] |
| [8] | J. J. Corso. Vision-Based Techniques for Dynamic, Collaborative Mixed-Realities. In B. J. Thompson, editor, Research Papers of the Link Foundation Fellows, volume 4. University of Rochester Press, 2004. Invited Report for Link Foundation Fellowship. [ bib ] |
| [9] | G. Ye, J. J. Corso, D. Burschka, and G. D. Hager. VICs: A Modular HCI Framework Using Spatio-Temporal Dynamics. Machine Vision and Applications, 16(1):13-20, 2004. [ bib ] |
| [10] | G. Ye, J. J. Corso, G. D. Hager, and A. M. Okamura. VisHap: Augmented Reality Combining Haptics and Vision. In Proceedings of IEEE International Conference on Systems, Man and Cybernetics, 2003. [ bib | .pdf ] |
| [11] | J. J. Corso, D. Burschka, and G. D. Hager. Direct Plane Tracking in Stereo Image for Mobile Navigation. In Proceedings of International Conference on Robotics and Automation, 2003. [ bib | .pdf ] |
| [12] | G. Ye, J. J. Corso, D. Burschka, and G. D. Hager. VICs: A Modular Vision-Based HCI Framework. In Proceedings of 3rd International Conference on Computer Vision Systems, pages 257-267, 2003. [ bib | .pdf ] |
| [13] | J. J. Corso, G. Ye, D. Burschka, and G. D. Hager. Software Systems for Vision-Based Spatial Interaction. In Proceedings of 2002 Workshop on Intelligent Human Augmentation and Virtual Environments, pages D-26 and D-56, 2002. [ bib ] |
Some more details
I am interested in the development of general methods for vision-based
interaction that allow dynamic, unencumbered interaction in environments
augmented with new display technology and both active and passive
vision-systems.
Iamwas involved in the
VICs project wherein we are investigating the development of a
general framework for vision-based human-computer interaction. The
project is based on two general ideas:
 Most recently, we have developed a new platform for unencumbered
interaction via a projected display passively monitored by uncalibrated
cameras: the 4D Touchpad (4DT) The system operates under the VICs
paradigm -- that is, coarse to fine processing in constrained setting to
minimize unnecessary computation. We built an eight-key piano as a
first demonstration of the system
[mpeg]. We are currently modifying TWM to operate under the 4DT
in order to demonstrate the versatility of this platform.
Most recently, we have developed a new platform for unencumbered
interaction via a projected display passively monitored by uncalibrated
cameras: the 4D Touchpad (4DT) The system operates under the VICs
paradigm -- that is, coarse to fine processing in constrained setting to
minimize unnecessary computation. We built an eight-key piano as a
first demonstration of the system
[mpeg]. We are currently modifying TWM to operate under the 4DT
in order to demonstrate the versatility of this platform.
VICs: A Modular Vision-Based HCI Framework
The paper can be found on the publications page.
Slides of the talk are here in pdf form [ color | b/w with notes ]
I
- Most interaction occurs in a constrained setting or region in the environment; i.e. a button must only observe the image region in its immediate neighborhood.
- Visual-Image processing is an expensive task and must be employed sparingly. Thus, if one observes the stream of visual cues in the image stream prior to a button push, one notices a "coarse-to-fine" progression of such cues: there is motion, then color, then shape, then gesture-matching. In coherence with the visual cues, we employ visual processing components in a similar fashion.
Most recently, we have developed a new platform for unencumbered
interaction via a projected display passively monitored by uncalibrated
cameras: the 4D Touchpad (4DT) The system operates under the VICs
paradigm -- that is, coarse to fine processing in constrained setting to
minimize unnecessary computation. We built an eight-key piano as a
first demonstration of the system
[mpeg]. We are currently modifying TWM to operate under the 4DT
in order to demonstrate the versatility of this platform.
Supplementary Information for ICVS 2003 Paper
VICs: A Modular Vision-Based HCI Framework
The paper can be found on the publications page.
Slides of the talk are here in pdf form [ color | b/w with notes ]
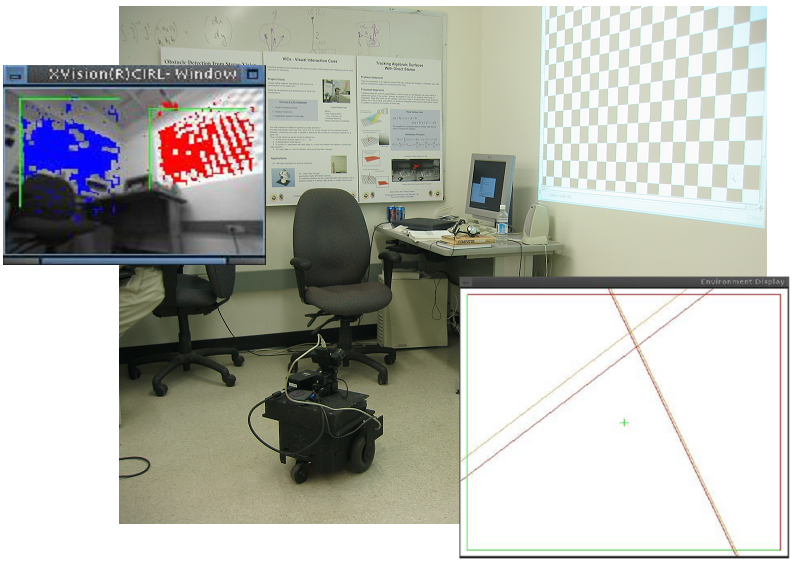
Surface Tracking

Many of the proposed Vision-based interfaces will be tied to a surface for the interface. We have developed a set of algorithms to directly track planar surfaces and parametric surfaces under a calibrated stereo-rig. Papers detailing this work are A movie demonstrating the planar surface tracking is here. A binary pixel mask is maintained which determines those pixel belonging to the plane (and with good texture); it is shown in red in the lower left of the video. The green vector being rendered is the plane's normal vector. Below is an image of the system that was built with our plane tracking routines to localize mobile robots. In the image, we show the real scene, the two walls that are being tracked (one in blue and one in red), and an overhead (orthogonal) projection of the reconstructed walls.