EECS 442: Computer Vision (Succeeding in EECS 442)
Why write this?
EECS 442 is a fairly demanding course in terms of project-based homework to start with. It is often the one of the first courses that people experience with fairly large leeway in how the assignments are done, less guidance in implementation, and a great deal more self-teaching. These issues don't go away when you're dealing with programming beyond the classroom.
After finding myself teaching various things in office hours, I've decided to put it in one document in the hopes of providing guidance and pointers that will hopefully make your life easier at any time (and you can get my first line of advice at whatever hour you happen to be doing things). Some of the advice here is obvious to some people, and so you can skip the sections that are obvious.
The guiding principle for everything other than dealing with incomplete specifications is that you should think of your work for this class as something like a science experiment. The pheomenon you are studying is the fact that your program produces bad output, runs too slow, or crashes. So, don't panic. Instead, take two deep breaths and then tackle things as analytically as possible.
Python tools & linear algebra resources
You should invest ten minutes each in figuring out how to the following tools to work at the level of just calling them when you're stuck or need an output. You don't need to be an expert but having a handle on these will make your life easier.
pdb:
To make a breakpoint, insert import pdb; pdb.set_trace()
To run a script and launch a debugger when there's an error, python -m ipdb -c continue NAME.py
imagemagick (available on most systems): e.g., convert input.png -resize 800x800 output.png
A very good linear algebra review and reference from Zico Kolter (and Chuong Do) here. You can safely ignore: determinants, the Hessian, gradients/Hessians for quadratic and linear functions, gradients of the determinant, and eigenvalues as optimization.
The Matrix Cookbook here. It's organized thematically and often the identities are very useful when you're stuck.
Meta-points
Here are a few things that may improve your results:
Come to class. You're adults and this is a 400-level class. I don't take attendance and I also record. You can experience this class by watching back-to-back computer vision lectures at midnight. It's not a good way to learn and will cost you time in the long run.
Stay on top of things. This stuff builds fairly cumulatively. If you look away for a while, your experience may look like this. If you skip a few critical classes and don't keep up, you may miss an entire abstraction that's used throughout a block of classes.
Success is time x effectiveness. You can put in lots of ineffective hours and get nothing done. Invest 30 minutes at the beginning of the semester to get comfortable with using pdb, matplotlib, and an effective workflow, and this will pay off.
Work and study in teams. If you're already doing well, then explaining to people is really the best way to cement your understanding. If you're not doing well, then you can find people who will explain things.
Start early on assignments
If you work for 4 hours and hit a brick wall, if you call it a night and spend 2 hours the next day, often the solution is obvious. If you don't have a next day, then you can't rely on this. In general, spending 4+2 hours on something is far better than spending 6 hours on it.
Your implementation may be slow
If you're not sure whether it's needed, include it. Asking “is it necessary” and waiting for an answer on piazza often takes as much time as including it.
Submit something for everything We can't give partial credit for blank pages, but if you write something about how you'd tackle the problem, these are the easiest points to give.
{kind=link}
Things to invest in
These take a little bit of time to do, but will pay themselves back over many times.
A debugger. At a minimum, you should be ok with print-style debugging. Ideally you should invest the time to learn pdb (hint: just insert import pdb; pdb.set_trace() wherever you want to stop the program and get a python prompt) or some editor with a built-in debugger (if your editor shows line numbers, try clicking them).
A way of looking at things. Figure out how to use matplotlib (or Jupyter notebooks) to see what things look like. If you're trying to look at an image by printing it out in a terminal, you're going to suffer needlessly.
An effective workflow. You want a workflow than ensures you can quickly write something and test it. If you have to transfer your files somewhere each time you change something, you will waste time. If you are doing something on a remote machine, invest in learning vi/vim, emacs, or something else that works in a terminal.
These reduce the amount of time that you spend waiting to get answers. Contrast these two options:
Sticking pdb.set_trace() before the function call that causes your program to crash, and trying changes (argument types, orders, etc) 5 times before it works;
Updating the code, scping/copypasting it, then running it from scratch 5 times until you get the thing to run.
Which runs faster? This can make orders of magnitude difference in debugging time.
Dealing with incomplete specifications, ambiguity
Most serious programming intrinsically involves incomplete specifications: if it was a complete specification, you'd ask a computer to do this. Unlike research or launching a startup, we're asking you to do something that we're certain is feasible. This is incredibly useful information. As an analogy, consider taking a math exam without a calculator: if you get a horrible expression, you know you're on the wrong track.
Incomplete specifications are difficult for two reasons:
You have to figure out how to write a fairly large, unconstrained program (see below);
You have to determine what parameters to use (see below).
They're somewhat orthogonal and you should tackle them independently.
Writing large, fairly unconstrained programs
Typically we give you some degree of flexibility in terms of how things are implemented. If you're used to more structured problems, this can difficult. Here are some strategies:
Break things into conceptually simple functions that do one thing and do only one thing. It's really easy to write a huge mess of code. This code tends to be easy to write and brutally difficult to debug. Give yourself a budget of maybe 30 lines per function and don't exceed this unless you absolutely have to. Be sure you can test each of the functions. Breaking things into conceptually simple components dramatically accelerates your debugging. If things are broken into pieces, you verify each component and the calling code, which is much easier than verifying all of the code stuck together since the functions prevent interactions (apart from global variables) between the pieces of code.
Don't have global variables. This is an invitation for hard-to-catch bugs.
Test every 10ish lines of code you write. Many of the variables are images or can be treated as images. Look at matplotlib and imshow. Your visual cortex is really good at pattern recognition. Use it!
Save intermediate results if it's a long-running computation. Use either np.save or pickle in Python, or use jupyter (that said, beware of jupyter caching things you don't intend! This is another bug waiting to happen). This caching reduces your time-to-find-bug.
Here's an example:
import numpy as np
import pickle
def stage1(args):
...
return results
def stage2(args):
...
return results
def stage3(args):
...
return results
if __name__ == "__main__":
cache = True
inputs = readSomething()
#stage 1
if not os.path.exists("output1.pck") or cache == False:
output1 = stage1(inputs)
pickle.save(output1,open("output1.pck",w"))
else:
output1 = pickle.load(open("output1.pck"))
#stage 2
if not os.path.exists("output2.pck") or cache == False:
output2 = stage2(output1)
pickle.save(output1,open("output2.pck",w"))
else:
output2 = pickle.load(open("output2.pck"))
#stage 3
output3 = stage3(output2)
Dealing with programs that crash
So your program crashes! The TAs and I have typically implemented each of the assignments ourselves, but possibly with other packages or languages. We also don't walk around with the documentation to python, numpy, and opencv in our heads. We usually have more experience than you debugging, but we are often seeing an error for the first time ourselves. Moreover, we didn't write the code that caused the error. Thus, even if you started programming in the past few years, you have a serious head-start on us.
Everytime you have an error:
Isolate the line of code that you've written that causes the error. This is in the traceback in python.
Read the error message. Even if it's cryptic: the person who wrote the error message thought it was potentially helpful. For instance, if it says something is wrong with the type of the argument, see if changing the type makes the error go away. If it says one of three things is potentially wrong, verify that your arguments satisfy all three requirements. If you attach a debugger right before the line that causes the program to crash, you can play with the arguments to the function that cause it to crash and dramatically reduce your debug time.
Google it, copy pasting the message. This is important! You don't want ‘‘python program crashes’’, you want ‘‘python numpy TypeError: data type not understood’’. Again, think of it as an investigation: there is probably a github issue, stack overflow question, website called ‘‘things I hate about numpy’’, or twitter post that contains your answer. Your job is to find it. Think of the challenge as generating the query that will find you the answer you need.
Attach a debugger right before the line and print out every single variable and look at them. Is anything sketchy?
Common things that I spotted in office hours or have been told as gotchas:
Wrong type
Wrong size of matrix
Nondeterministic functions being assumed to be deterministic (e.g., os.listdir)
Cached variables or a variable being used from further up in the code
Transposed results (looking at row instead of column and vice-versa)
Modifying things in place vs sending a copy back
Dealing with programs that don't do what you want (i.e., incorrect output)
So the program you wrote produces incorrect results. Your job now is to (a) identify where in the program the incorrect outputs come from and (b) identify why. Searching for why throughout the program is really hard; searching for where is often easier.
Here are a few strategies:
Assume libraries are correct. You should (largely) assume that numpy, python, etc. are correctly implemented. HOWEVER, you may be simply calling something incorrectly: you may have the order or types of the functions incorrect.
What parts of the program don't work? If your program can't be broken into small pieces, then you can't test each one. If you don't know what the input and output of each function is, then you'll have more success debugging if you identify this.
Make fake input data that you know the answer to and that the program should work on. Typically you're working with data that you don't fully understand and a specification you're working to get working. So start with something really simple so you get rid of one variable of uncertainty. If you're trying to:
line up images: take the same image and use np.roll to offset them
classify things: make a small version of the dataset where each ‘‘class’’ is just a color like blue, red, green.
find correspondences in images: use np.roll to make an unaligned image
fit a transformation between points: generate a set of random points
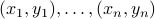 and their corresponding points
and their corresponding points 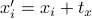 for some translation (or some affine transformation you pick)
for some translation (or some affine transformation you pick)fit a regression model: generate some random NxF data matrix
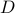 , a random Fx1 vector
, a random Fx1 vector 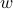 , Nx1 noise vector
, Nx1 noise vector
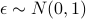 and set
and set 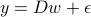 . Do you get back?
. Do you get back?fit a classification model: generate positive feature vectors according to a normal distribution centered at
 in all dimensions and
negatives according to a normal distribution centered at
in all dimensions and
negatives according to a normal distribution centered at 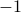 in all dimensions.
in all dimensions.find something involving epipolar geometry: generate an image that is rolled to the right along the x axis.
fit something on top of something extracted from the image: hand-mark what you want (e.g., correspondences) and try
I'll add more as I suggest more
Print the program state If you've broken your code into simple functions, at every step, print out everything and see if it looks reasonable. If you have concerns or nagging feelings, go back.
Once you know where, identify why Once you've identified the parts of the program that are likely ok and ones that aren't, start trying to identify why the part of the program isn't working. Go line-by-line and try to explain what each line does verbally no, really. If you're really stuck, you think that you conceptually understand what the function is supposed to do, but there's some bug that won't go away, consider rewriting it from scratch.
Dealing with programs that have knobs on the sides (i.e., what parameters do I use)
Often there are parameters that are left as design decisions. This is because there really aren't particular numbers that work or are mathematically elegant.
What are default parameters? If you're expected to use something, read the documentation for parameters. If you use the parameters that are specified as default values or are suggested in the documentation, you probably won't have many issues. If you're implementing something, look at the manual for something that has already implemented it. Does it provide a knob to turn for the parameter you're curious about? What value does it set by default?
To see effects, try orders of magnitude. If you want to know if twiddling the knob on a parameter will make a difference in the output, don't try changing things by a factor of 20%. Be bold! Multiply the parameter by 10 or 100! The worst case is that the program crashes or behaves unexpectedly; however its unexpected behavior may tell you about what that knob does.
Dealing with slow programs
Invest in a profiler (python comes with one) or put a bunch of print statements. Don't prematurely optimize anything.
It's almost always faster if you can call some function in numpy or scipy to do your work. It'll call code that was written in Fortran or C and is well-optimized.
In vision with python (or anything that's not compiled), avoid for loops. Given a 1000x1000 image, the for loop inner body executes 1 million times. The overhead on this loop is not insubstantial
Tricks:
Remember data structures and algorithms: iterating through lists is SLOW. Looking up in a hash table / dictionary is fast.
Use masks to modify things conditionally inside a matrix. For instance, if X is a matrix, X[X<0] = 0 sets all the negative entries to zero.
Store things as a numpy array whenever possible. This forces you to try to write things with numpy rather than with a list and will guide you to writing reasonably fast code.