A2D
Actor-Action Dataset
Information and Data Download

Jason J. Corso
| Overview | |
| Description | |
| Downloads | |
| Publications |
Back to Research Pages
A2D: A Dataset and Benchmark for Action Recognition and Segmentation with Multiple Classes of Actors
Primary Contributors: Chenliang Xu and Jason J. Corso (Emails: jjcorso@eecs.umich.edu,cliangxu@umich.edu)
Overiew: Can humans fly? Emphatically no. Can cars eat? Again, absolutely not. Yet, these absurd inferences result from the current disregard for particular types of actors in action understanding. There is no work we know of on simultaneously inferring actors and actions in the video, not to mention a dataset to experiment with. A2D hence marks the first effort in the computer vision community to jointly consider various types of actors undergoing various actions. To be exact, we consider seven actor classes (adult, baby, ball, bird, car, cat, and dog) and eight action classes (climb, crawl, eat, fly, jump, roll, run, and walk) not including the no-action class, which we also consider. The A2D has 3782 videos with at least 99 instances per valid actor-action tuple and videos are labeled with both pixel-level actors and actions for sampled frames. The A2D dataset serves as a novel large-scale testbed for various vision problems: video-level single- and multiple-label actor-action recognition, instance-level object segmentation/co-segmentation, as well as pixel-level actor-action semantic segmentation to name a few.
Findings: Our CVPR 2015 paper formulates the general actor-action understanding problem and instantiate it at various granularities: both video-level single- and multiple-label actor-action recognition and pixel-level actor-action semantic segmentation. Our experiments demonstrate that inference jointly over actors and actions outperforms inference independently over them, and hence concludes our argument of the value of explicit consideration of various actors in comprehensive action understanding.
Description
We have collected a new dataset consisting of 3782 videos from YouTube; these videos are hence unconstrained in-the-wild videos with varying characteristics. Figure 1 has single-frame examples of the videos. We select seven classes of actors performing eight different actions. Our choice of actors covers articulated ones, such as adult, baby, bird, cat and dog, as well as rigid ones, such as ball and car. The eight actions are climbing, crawling, eating, flying, jumping, rolling, running, and walking. A single action class can be performed by various actors, but none of the actors can perform all eight actions. For example, we do not consider adult-flying or ball-running in the dataset. In some cases, we have pushed the semantics of the given action term to maintain a small set of actions: e.g., car-running means the car is moving and ball-jumping means the ball is bouncing. One additional action label none is added to account for actions other than the eight listed ones as well as actors in the background that are not performing an action. Therefore, we have in total 43 valid actor-action tuples.

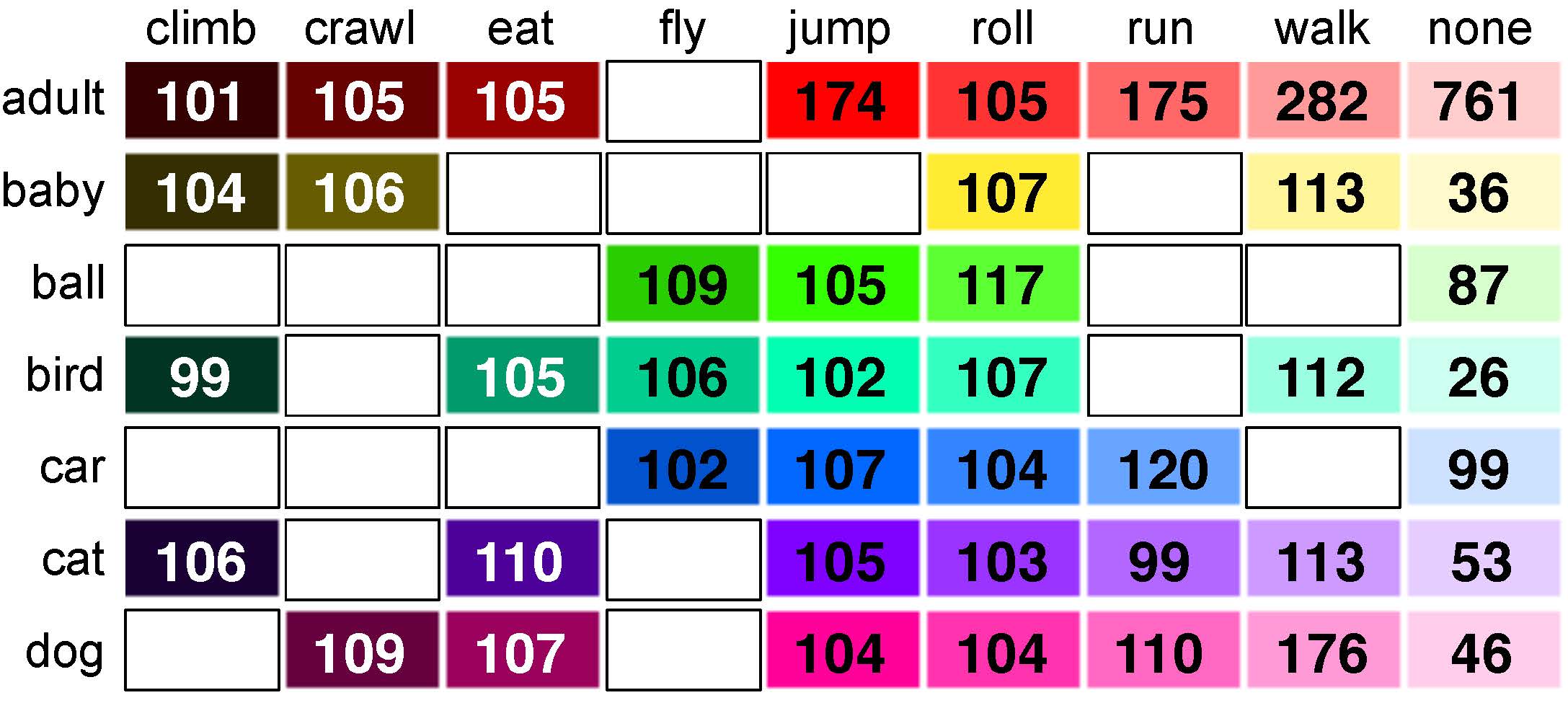
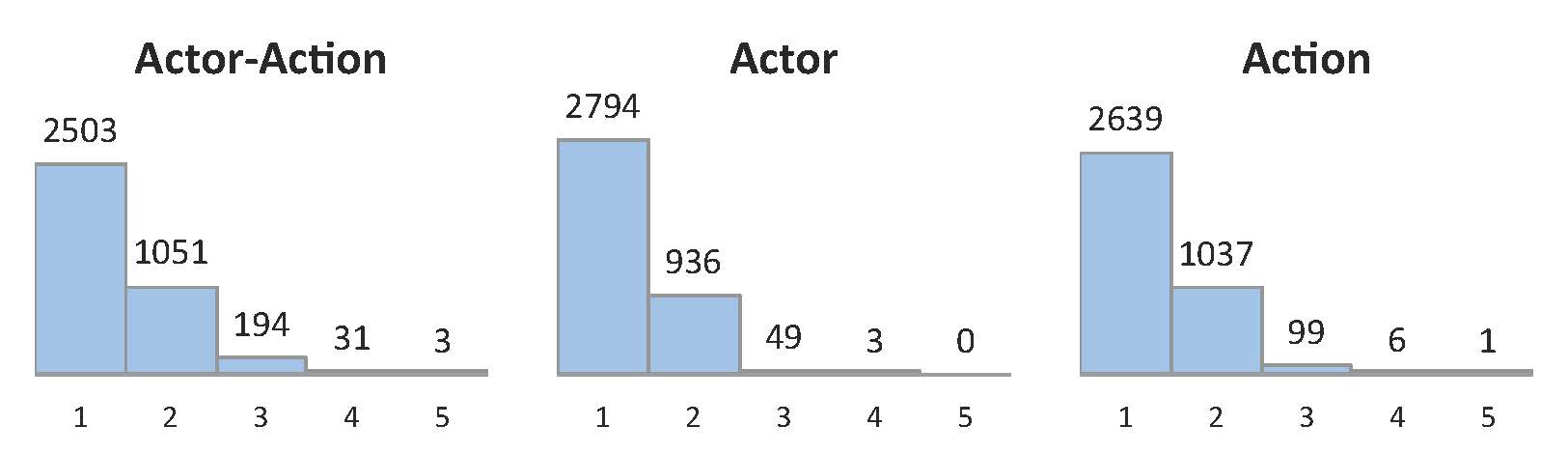
To query the YouTube database, we use various text-searches generated from actor-action tuples. Resulting videos were then manually verified to contain an instance of the primary actor-action tuple, and subsequently temporally trimmed to contain that actor-action instance. The trimmed videos have an average length of 136 frames, with a minimum of 24 frames and a maximum of 332 frames. We split the dataset into 3036 training videos and 746 testing videos divided evenly over all actor-action tuples. Figure 2 shows the statistics for each actor-action tuple. One-third of the videos in A2D have more than one actor performing different actions, which further distinguishes our dataset from most action classification datasets. Figure 3 shows exact counts for these cases with multiple actors and actions.
To support the broader set of action understanding problems in consideration, we label three to five frames for each video in the dataset with both dense pixel-level actor and action annotations (Figure 1 has labeling examples). The selected frames are evenly distributed over a video. We start by collecting crowd-sourced annotations from MTurk using the LabelMe toolbox, then we manually filter each video to ensure the labeling quality as well as the temporal coherence of labels. Video-level labels are computed directly from these pixel-level labels for the recognition tasks. To the best of our knowledge, this dataset is the first video dataset that contains both actor and action pixel-level labels.
Downloads License: The dataset may not be republished in any form without the written consent of the authors.
- README
- Dataset and Annotation (version 1.0, 1.9GB, [tar.bz])
- Evaluation Toolkit (version 1.0,
[tar.bz])
We provide evaluation code for pixel-level actor-action semantic segmentation and ground truth labels for video-level actor-action single- and multiple-label recognition.
| [1] | Y. Yan, C. Xu, D. Cai, and J. J. Corso. Weakly supervised actor-action segmentation via robust multi-task ranking. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017. [ bib ] |
| [2] | C. Xu and J. J. Corso. Actor-action semantic segmentation with grouping-process models. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016. [ bib | data ] |
| [3] | C. Xu, S.-H. Hsieh, C. Xiong, and J. J. Corso. Can humans fly? Action understanding with multiple classes of actors. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2015. [ bib | poster | data | .pdf ] |