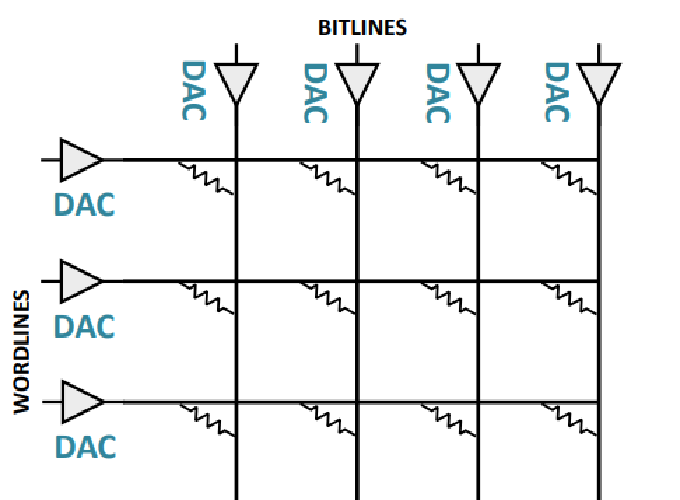
Non-Volatile Memories (NVMs) create opportunities for advanced in-memory computing. By re-purposing memory structures, certain NVMs have been shown to have in-situ analog computation capabilities. For example, resistive memories (ReRAMs) store the data in the form of resistance of titanium oxides, and by injecting voltage into the word line and sensing the resultant current on the bit-line, the dot-product of the input voltages and cell conductances is obtained using Ohm’s and Kirchhoff’s laws.
Recent works have explored the design space of ReRAM-based accelerators for machine learning algorithms by leveraging this dot-product functionality. Despite significant performance gain offered by computational NVMs, previous works have relied on manual mapping of convolution kernels to the memory arrays, making it difficult to be configured for diverse applications. We combat this problem by proposing a programmable in-memory processor architecture and programming framework.
The efficiency of an in-memory processor comes from two sources. The first is massive data parallelism. NVMs are composed of several thousands of arrays. Each of these arrays are transformed into a single instruction multiple data (SIMD) processing unit that can compute concurrently. The second source is a reduction in data movement by avoiding shuffling of data between memory and processor cores. Our goal is to design an architecture, establish the programming semantics and execution models, and develop a compiler, so as to expose the above benefits of ReRAM computing to general purpose data parallel programs.
