Exposition
A sporadic blog containing interesting ideas encountered, clarification of proofs read, and other expository snippets.
An Upper Bound on 2-List-Decodable Codes
Proof of Theorem 4 of [Ashikhmin-Barg-Litsyn,2002]
February 2023
In A New Upper Bound on Codes Decodable into Size-2 Lists, Ashikhmin, Barg, and Litsyn analyze the distance distribution of binary codes to give an upper bound on the cardinality of codes decodable into lists of two candidate messages. The proof of the main result is very terse, so the intention of this post is to fill in the details and provide a supplementary aid for other readers.
show/hide details
A binary code \(C\subseteq \mathbb{F}_2^n\) is said to be a \((2, \rho n)\)-list-decodable code if every \(\rho n\)-radius ball in \(\mathbb{F}_2^n\) contains at most 2 codewords. The main result, stated as Theorem 4 in the paper, gives an upper bound for the fraction of errors \(\rho\) for any \((2, \rho n)\)-list-decodable code \(C\subseteq \mathbb{F}_2^n\) of rate \(R\).
There are two main lemmas used to prove this 2-list-decoding upper bound: one is an upper bound for unique-decoding and the other is a bound on a certain component of the distance distribution.
For unique-decoding of binary codes, the best known upper bound for the relative distance of a code with a given rate is a combination of the MRRW bound and an improvement by Levenshtein and Samorodnitsky. The MRRW bound says that for a binary code of rate \(R\) whose codewords have constant weight \(\alpha n\), the relative minimum distance is bounded above by $$\delta(R,\alpha)\leq \delta_{LP}(R,\alpha):= 2\frac{\alpha(1-\alpha)-h^{-1}(R)(1-h^{-1}(R))}{1+2\sqrt{h^{-1}(R)(1-h^{-1}(R))}},$$ for \(h^{-1}(R)\leq\alpha\leq\frac{1}{2}\). Here \(h\) denotes the binary entropy function. This bound is minimized by the relative weight $$\alpha=\alpha^*(R):=\mathop{\text{argmin}}_{ \substack{0\leq\alpha\leq\beta\leq\frac{1}{2}\\ h(\alpha)-h(\beta)=1-R}} \left\{2\frac{\alpha(1-\alpha)-\beta(1-\beta)}{1+2\sqrt{\beta(1-\beta)}}\right\}. $$ Note that \(\beta\) here is a dummy variable uniquely determined by \(\alpha\) and \(R\). We denote this optimal upper bound by \(\delta_{LP}(R):=\delta_{LP}(R,\alpha^*)\). The improvement by Levenshtein and Samorodnitsky gives a tighter bound for a certain interval for \(\alpha\). The results above are formally summarized in the paper as the following theorem.
Theorem 2: For any code \(C\subseteq\mathbb{F}^n\) of rate \(R\in (0,1)\) and constant weight \(\alpha n\), its relative distance is bounded by $$\delta(R,\alpha)\leq\delta_{up}(R,\alpha):= \begin{cases} \delta_{LP}(R,\alpha), &h^{-1}(R)\leq\alpha\leq\alpha^*(R)\\ \delta_{LP}(1+R-h(\alpha)), &\alpha^*(R)\leq\alpha\leq\frac{1}{2}.\\ \end{cases}$$
The second lemma, stated as Theorem 3 in the paper, is a result by Litsyn and says that for any code of rate \(R\), there exists a small ball centered at the origin such that the number of codewords it contains is exponential in \(R\). This dense ball is a large component of the distance distribution of the code. Recall that the distance distribution of a code \(C\subseteq\mathbb{F}^n\) is a vector \((A_0,A_1,...,A_n)\) whose \(i^\text{th}\) entry specifies the average number of pairs of codewords at distance \(i\) from each other. More formally, $$A_i:=\frac{1}{|C|}\left|\left\{(c,c')\in C^2\ :\ d(c,c')=i\right\}\right|=\mathop{\mathbb{E}}_{c\in C}\left[\left|\{c'\in C : d(c,c')=i\}\right|\right].$$ Using this notation, we can state Litsyn's result more formally:
Theorem 3: For any code \(C\subseteq\mathbb{F}^n\) of rate \(R\in (0,1)\) and large enough \(n\), there exists a $$0\leq\xi\leq 2\frac{\alpha(1-\alpha)-\beta(1-\beta)}{1+2\sqrt{\beta(1-\beta)}}$$ such that \(A_{\xi n}\geq 2^{n\cdot \bar{R}(\alpha,\beta,\xi)}\), where \(0\leq\alpha\leq\beta\leq\frac{1}{2}, h(\alpha)-h(\beta)=1-R\), and \(\bar{R}\) is some complicated function (see the original paper for details).
Now we can formally state the main theorem:
Theorem 4: Let \(C\) be a \((2,\rho n)\)-list-decodable code with rate \(R\in (0,1)\). Then $$\rho \leq \rho(2,R)\leq \frac{1}{2}\min_{\alpha,\beta}\left\{\max_{\xi}\left\{\delta_{up}(\bar{R}(\alpha,\beta,\xi),\delta_{lp}(R))\right\}\right\},$$ where \(\bar{R}(\alpha,\beta,\xi), \alpha, \beta,\) and \(\xi\) are from Theorem 3.
To prove this result, we must show that any ball containing two codewords has radius at most \(n\) times the claimed upper bound. It is enough to show that there exists a ball containing three codewords that has radius strictly larger than \(n\) times the claimed upper bound. The diagram below gives an example of these equivalent statements.
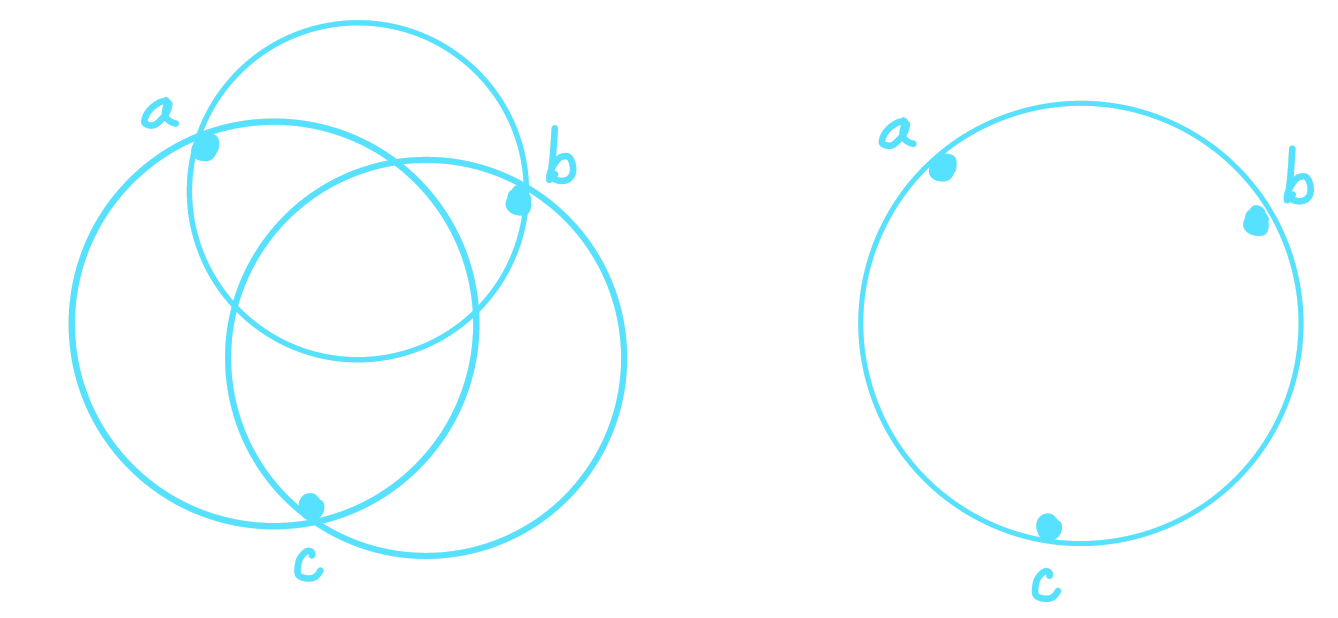
Proof: Let \(\alpha=\alpha^*(R)\) be the parameter that optimizes the MRRW bound for this code (as defined above) and \(\beta\) be the corresponding parameter uniquely determined by \(\alpha\) and \(R\). For this choice of parameters, the upper bound on the radius in Theorem 3 satisfies \(\xi\leq\delta_{LP}(R)\). By Theorem 2, the best upper bound for unique-decoding of \(C\) for this choice of \(\alpha\) is \(\delta_{up}(R,\alpha^*(R))=\delta_{LP}(R,\alpha^*(R))=\delta_{LP}(R)\). By Theorem 3, there exists a radius \(\xi\leq\delta_{LP}(R)\) such that the component \(A_{\xi n}\) of the distance distribution satisfies \(A_{\xi n}\geq 2^{n\cdot \bar{R}(\alpha,\beta,\xi)}\). Since \(A_{\xi n}\) is the expected number of codewords at a distance of \(\xi n\) from some codeword \(a\), for any codeword \(a\in C\), there must exist a codeword \(a\in C\) with \(A_{\xi n}\) neighbours at a distance of \(\xi n\) from it. Thus for this \(\xi\), the \(\xi n\)-radius sphere \(S(\xi n,a)\) centered at \(a\) contains \(A_{\xi n}\) codewords.
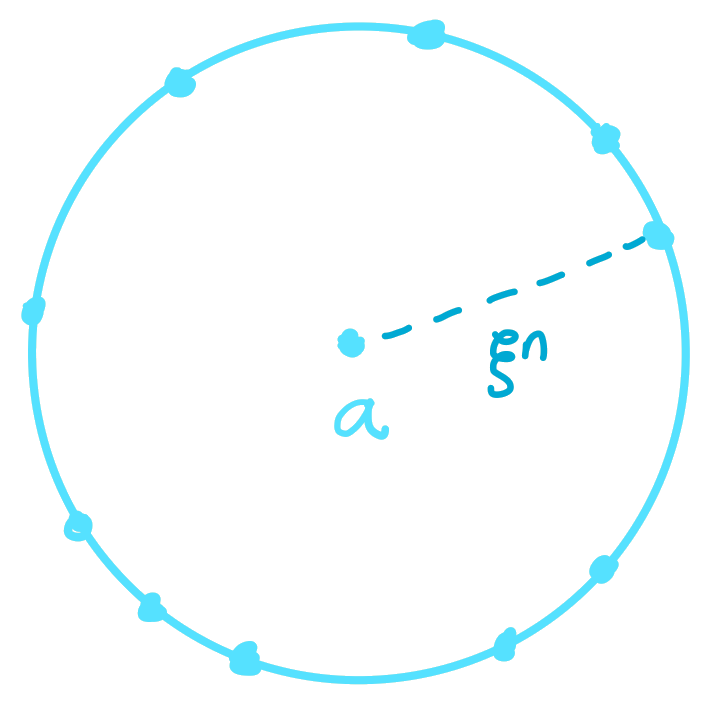
Now we shift the space \(\mathbb{F}_2^n\) by \(a\) to shift the center of this sphere to the origin. This transformation leaves the space unchanged and makes the sphere into a constant \(\xi n\)-weight code, which we denote by \(C'\). As an example, consider the shifting of 3-dimensional binary space in the diagram below.
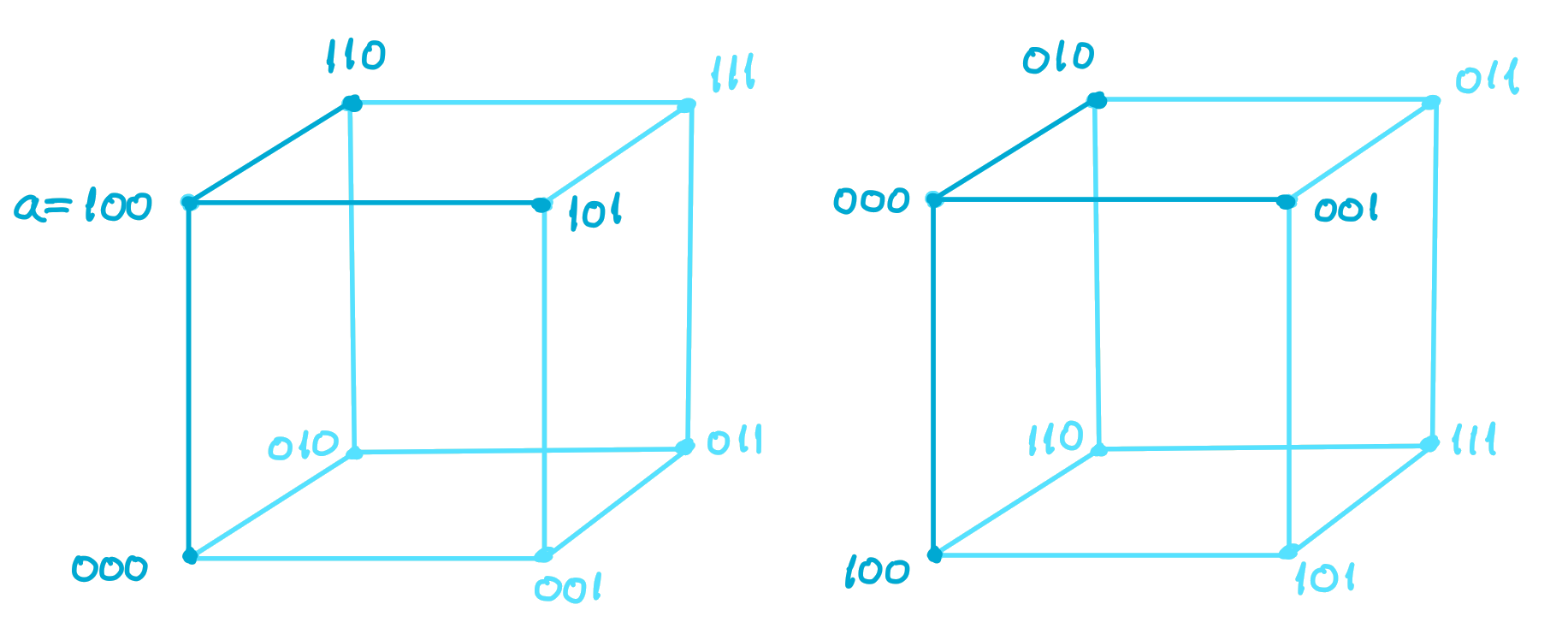
Note that this code has rate \(R'\leq R\), so its relative distance satisfies \(\delta'\geq\delta\). By Theorem 2, the relative distance of \(C'\) satisfies \(\delta'\leq\delta_{up}(R',\xi)\).
Take an arbitrary pair of codewords \(c',c''\in C'\) such that the distance between them is \(d(c',c'')=n\cdot\delta_{up}(R',\xi)\). By construction, the weights of these codewords are \(wt(c')=\xi n=wt(c'')\). Equivalently, \(d(0,c')=\xi n=d(0,c'')\). Since \(0\in C'\), we have \(d(0,c')=\xi n\leq n\cdot\delta_{up}(R',\xi)\). Consider a smallest ball containing \(c', c'',\) and \(0\). Note that we assume \(d(c',c'')=n\cdot\delta_{up}(R',\xi)\) to deal with the worst-case scenario; if the distance is less, then the ball is smaller, which is better for our purpose. Denote the center of this ball by \(b\in\mathbb{F}_2^n\). By construction, its radius is \(rad(\{0,c',c''\})=d(0,b)=wt(b)\). We claim that the radius of this ball satisfies \(rad(\{0,c',c''\})=\frac{1}{2}n\cdot\delta_{up}(R',\xi)\), which is strictly greater than the upper bound claimed in Theorem 4.
To prove the claim, we show both sides of the equality. For the "\(\geq\)" case, we use the fact that radius \(rad(\{0,c',c''\})\) is at least half of the diameter of the smallest ball containing \(c', c'',\) and \(0\). This can be written as $$\begin{align*} wt(b)&=rad(\{0,c',c''\})\\ &\geq\frac{1}{2} diam(\{0,c',c''\})\\ &=\frac{1}{2}\max\{d(0,c'),d(0,c''),d(c',c'')\}\\ &=\frac{1}{2}\max\{\xi n, n\cdot\delta_{up}(R',\xi)\}\\ &=\frac{1}{2}n\cdot\delta_{up}(R',\xi). \end{align*}$$ Here the last two inequalities follow by construction. For the "\(\leq\)" case, we use the following lemma.
Lemma: \(\max\{d(b,c'),d(b,c''),d(b,0)\}\leq\frac{1}{2}\max\{d(0,c')=d(0,c''), d(c',c'')\}\).
From this lemma, we obtain $$\begin{align*} wt(b)&=d(0,b)\\ &\leq\max\{d(b,c'),d(b,c''),d(b,0)\}\\ &\leq\frac{1}{2}\max\{d(0,c')=d(0,c''), d(c',c'')\}\\ &=\frac{1}{2}\max\{\xi n, n\cdot\delta_{up}(R',\xi)\}\\ &=\frac{1}{2}n\cdot\delta_{up}(R',\xi). \end{align*}$$ Therefore, the radius of the smallest ball containing the three codewords \(c', c'',\) and \(0\) is \(\frac{1}{2}n\cdot\delta_{up}(R',\xi)\).
Now it remains to prove the lemma.
The codewords \(c', c'',\) and \(0\) and their center \(b\) are elements in \(\mathbb{F}_2^n\), so the distances between them can be obtained by comparing their corresponding bitstrings.
Slightly abusing notation, denote the corresponding bitstring representations by \(c',c'',0,b\in\{0,1\}^n\), respectively.
Write the distance \(d(c',0)=d(c'',0)=x+y\) for some \(1\leq x,y\leq n\).
Then \(d(c',c'')=2x\).
Without loss of generality, assume that all the ones in the bitstring representation are in continuous blocks for \(c'\) and \(c''\), as shown in the diagram below.
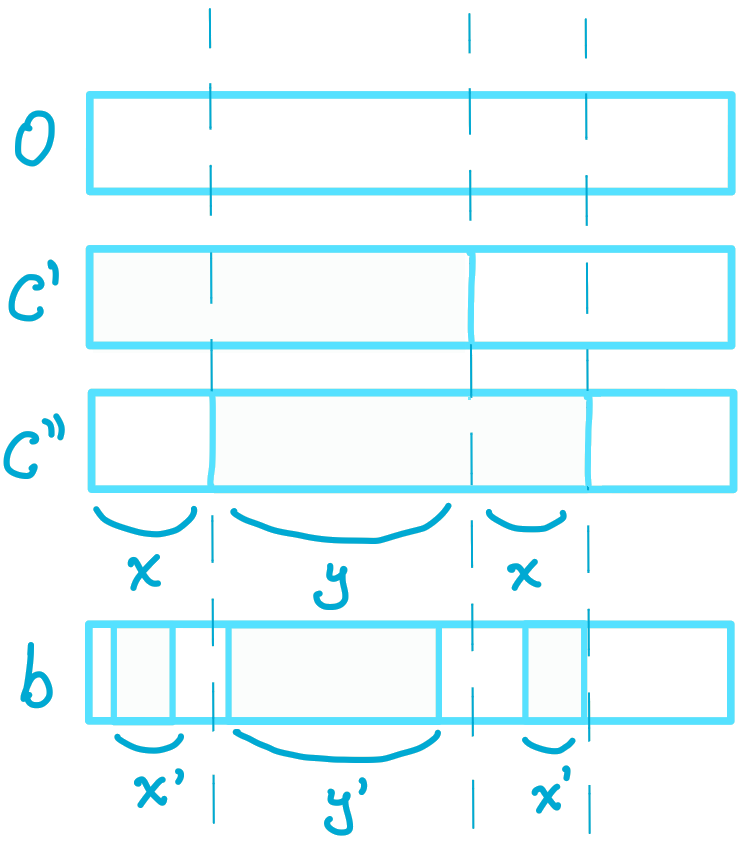
By definition, \(b\) must minimize its distance to \(c',c''\) and \(0\), so it must have \(x'\leq x\) ones in the first and third regions above and \(y'\leq y\) ones in the second.
Thus, we can write the distances as
$$\begin{align*}
d(b,0)&=2x'+y'\\
d(b,c')&=x-x'+y-y'+x'=x+y-y'\\
d(b,c'')&=x'+y-y'+x-x'=x+y-y'.
\end{align*}$$
Since \(b\) minimizes the distances \(d(b,0), d(b,c'), d(b,c'')\), we can set \(x'=0\), so \(d(b,0)=y'\).
There are two cases to consider:
If \(x\leq y\), then the best case for minimization is when the distances are all equal, \(d(b,0)=d(b,c')=d(b,c'')\). In this case, \(y'=x+y-y'\), and so \(y'=\frac{1}{2}(x+y)\). The assumption \(x\leq y\) implies that \(y'\leq y\), which is true by construction. Hence, $$wt(b)=y'=\frac{1}{2}(x+y)\leq \frac{1}{2}\max\{x+y,2x\},$$ so the claim is true.
If \(x>y\), then \(d(b,c')=d(b,c'')=x+y-y'\) is minimized when \(y'=y\). In this case, \(d(b,c')=d(b,c'')=x\). Hence, $$wt(b)=y'=y \lt x=\frac{1}{2}2x=\frac{1}{2}\max\{x+y,2x\},$$ so the claim is true.
\(\square\)
Strong Extractors and Soft-Decodable Codes are Equivalent
Proof of Theorem 1 of [Ta-Shma,Zuckerman,2004]
November 2022
In their paper, Extractor Codes, Ta-Shma and Zuckerman show an equivalence between randomness extractors and error-correcting codes. In particular, every strong extractor determines a good soft-decodable code, and vice versa (with some loss in parameters). The proof of this equivalence is somewhat terse, so the intention of this post is to provide the omitted steps and details in the hope that it will help other readers.
show/hide details
A strong extractor \(Ext:\{0,1\}^n\times\{0,1\}^{\log_2(d)}\to\{0,1\}^m\) determines a corresponding extractor code \(C_{Ext}\), which is defined in the following way: For any input \(c\in\{0,1\}^n\), let \(z(c):=(z_1,...,z_d)\in\{0,1\}^{md}\), where \(z_i:=Ext(c,i)\). In other words, \(z(c)\) is the tuple of all possible extractor outputs for input \(c\) when paired with all possible strings from the random source. Then \(C_{Ext}:=\left\{z(c) : c\in\{0,1\}^n\right\}\subseteq\{0,1\}^{md}\) is the set of all such tuples. The equivalence theorem states:
Theorem 1:
(i) If \(Ext:\{0,1\}^n\times\{0,1\}^{d}\to\{0,1\}^m\) is a strong \((\ell,\epsilon)\)-extractor, then \(C_{Ext}\) is combinatorially \((\ell,\epsilon)\)-soft-decodable.
(ii) If \(C_{Ext}\) is combinatorially \((\ell, \epsilon)\)-soft-decodable, then \(Ext\) is a strong \((\frac{\ell}{\epsilon},2\epsilon)\)-extractor.
The proof of the converse (ii) is rather straightforward in the original paper, so only the proof of (i) will be presented here. The proof proceeds by contradiction.
For simplicity, denote \([N]:=\{0,1\}^n\), \([D]:=\{0,1\}^d\), and \([M]:=\{0,1\}^m\). Also let \(\mathcal{U}_{[D]}\) denote the uniform distribution over the set \([D]\). Suppose \(Ext:[N]\times[D]\to[M]\) is a strong \((\ell,\epsilon)\)-extractor. Then for any \(\ell\)-source \(\mathcal{X}\) over \([N]\), the output of the extractor looks uniform even when the random string is provided. More formally, if \(\mathcal{X}(x)\leq\frac{1}{\ell}\) for all \(x\in[N]\), the statistical distance between the joint distribution \((\mathcal{U}_{[D]},Ext(\mathcal{X},\mathcal{U}_{[D]})\) and the uniform distribution \(\mathcal{U}_{[D]\times[M]}\) is \(\epsilon\). Let \(C\subseteq[M]^D\) be the extractor code corresponding to \(Ext\). and \(w:[D]\times[M]\to[0,1]\) be a weight function for \(C\). This weight function gives the probability that a given string was sent in a given coordinate of the codeword, that is \(w(i,z)=\mathbb{P}[z\text{ was sent in coordinate }i]\). To show that \(C\) is combinatorially \((\ell, \epsilon)\)-soft-decodable, we must show that its agreement set \(\mathcal{A}_\epsilon(w)=\{c\in C: \sum_{i\in[D]}w(i,c_i)>(\rho(w)+\epsilon)D\}\) has size at most \(\ell\). Here \(\rho(w)\) is the relative weight of \(w\) (as defined in section II.A).
For the sake of contradiction, suppose that \(\mathcal{A}_\epsilon(w)\) contains more than \(\ell\) codewords. We want to show that \(Ext\) cannot be a strong \((\ell,\epsilon)\)-extractor in this case. To this end, it is enough to find an \(\ell\)-source and an algorithm that distinguishes between the distributions \((\mathcal{U}_{[D]},Ext(\mathcal{X},\mathcal{U}_{[D]})\) and \(\mathcal{U}_{[D]\times[M]}\) with probability greater than \(\epsilon\). The large agreement set indicates how the \(\ell\)-source and distinguisher should be constructed: By definition, every element from the agreement set \(\mathcal{A}_\epsilon(w)\) corresponds to an input to the extractor, so these \(n\)-bit inputs will comprise the \(\ell\)-source. To construct a distinguisher, we note that any uniformly random element \(u\in[M]^D\) will agree with the weight function \(w\) with factor \(\rho(u)\), while any elements from \(\mathcal{A}_\epsilon(w)\) agree with factor \(\rho(u)+\epsilon\). This difference in agreement factors allows us to distinguish between uniformly random elements and elements from the agreement set.
Now we formalize this argument. Consider the test algorithm \(W:[D]\times[M]\to\{0,1\}\) that outputs \(W(i,z):=1\) with probability \(w(i,z)\) and outputs \(W(i,z):=0\) with probability \(1-w(i,z)\). Note that this algorithm can act on distributions over \([D]\times[M]\). We will show that for a certain \(\ell\)-source, this \(W\) algorithm acts as the desired distinguisher. By construction, $$\begin{align*} \mathbb{P}\left[W(\mathcal{U}_{[D]\times[M]})=1\right] &=\mathbb{P}_{(i,z)\gets\mathcal{U}_{[D]\times[M]}}\left[W(i,z)=1\right]\\ &=\sum_{u\in[D]\times[M]}\mathbb{P}_{(i,z)\gets\mathcal{U}_{[D]\times[M]}}\left[(i,z)=u\right]\cdot\mathbb{P}[W(u)=1]\\ &=\sum_{u\in[D]\times[M]}\frac{1}{DM}\cdot w(u)\\ &=\sum_{(i,z)\in[D]\times[M]}\frac{1}{DM}\cdot w(i,z)\\ &=\rho(w). \end{align*}$$
Since \(Ext\) is a function whose image is in \([M]\), the preimage of \(\mathcal{A}_\epsilon(w)\subseteq C\subseteq [M]^D\) under a coordinate-wise application of \(Ext\) is some \(B:=Ext^{-1}(\mathcal{A}_\epsilon(w))\subseteq [N]\). Then the size of \(B\) must satisfy \(|B|\geq|\mathcal{A}_\epsilon(w)|>\ell\). Consider \(\mathcal{U}_B\), the uniform distribution over \(B\). By assumption, \(|B|>\ell\), so \(\mathcal{U}_B(x)<\frac{1}{\ell}\) for all \(x\in[N]\), which implies that \(\mathcal{U}_B\) is an \(\ell\)-source over \([N]\). This \(\mathcal{U}_B\) is the \(\ell\)-source we use to derive a contradiciton. Since \(Ext\) is a strong \((\ell,\epsilon)\)-extractor, the statistical distance between \((\mathcal{U}_{[D]},Ext(\mathcal{U}_B,\mathcal{U}_{[D]})\) and \(\mathcal{U}_{[D]\times[M]}\) is at most \(\epsilon\). Denote this joint distribution over \([D]\times[M]\) by \(\mathcal{D}':=(\mathcal{U}_{[D]},Ext(\mathcal{U}_B,\mathcal{U}_{[D]})\). Then applying \(W\), we have $$\begin{align*} \mathbb{P}\left[W(\mathcal{D}')=1\right] &=\mathbb{P}_{(x,y)\gets\mathcal{D}'}\left[W(x,y)=1\right]\\ &=\mathbb{P}_{y\gets\mathcal{U}_B}\left[\mathbb{P}_{x\gets\mathcal{U}_{[D]}}\left[W(x,Ext(y,x))=1\right]\right]\\ &=\sum_{b\in B}\mathbb{P}_{y\gets\mathcal{U}_B}[y=b]\cdot\mathbb{P}_{y\gets\mathcal{U}_B}\left[\mathbb{P}_{x\gets\mathcal{U}_{[D]}}\left[W(x,Ext(y,x))=1\right]\ |\ y=b\right]. \end{align*}$$ For any \(y\) drawn from \(\mathcal{U}_{B}\), the inner probability above can be written as $$\begin{align*} \mathbb{P}_{x\gets\mathcal{U}_{[D]}}\left[W(x,Ext(y,x))=1\right] &=\sum_{a\in[D]}\mathbb{P}_{x\gets\mathcal{U}_{[D]}}\left[x=a\right]\cdot\mathbb{P}_{x\gets\mathcal{U}_{[D]}}\left[W(x,Ext(y,x))=1\ |\ x=a\right]\\ &=\frac{1}{D}\sum_{a\in[D]} w(a,Ext(y,a))\\ &>\frac{1}{D}(\rho(w)+\epsilon)D\\ &=\rho(w)+\epsilon, \end{align*}$$ where the inequality follows from the definition of the agreement set and the fact that \(y\) is an element of its preimage. Using this, the probability above is bounded by $$\mathbb{P}\left[W(\mathcal{D}')=1\right]>|B|\frac{1}{|B|}(\rho(w)+\epsilon)=\rho(w)+\epsilon.$$ Hence for this \(W\), we have \(\left|\mathbb{P}\left[W(\mathcal{D}')=1\right]-\mathbb{P}\left[W(\mathcal{U}_{[D]\times[M]})=1\right]\right|>\left|\rho(w)+\epsilon-\rho(w)\right|=\epsilon.\) This means that \(W\) can distinguish between distributions \(\mathcal{D}'\) and \(\mathcal{U}_{[D]\times[M]}\) with advantage greater than \(\epsilon\). Thus, \(\mathcal{D}'\) is not \(\epsilon\)-close to uniform, which contradicts the assumption that \(Ext\) is a strong \((\ell,\epsilon)\)-extractor.
\(\square\)