EECS 489 PA1: Peer-to-Peer Search
This assignment is due on Friday,
29 Jan 2016, 6 pm.
Preamble
Review the grading policy
page on the course website. Remember that to incorporate publicly available
code in your solution is considered cheating in this course.
To pass off the implementation of an algorithm as that
of another is also considered cheating. If you can not implement
a required algorithm, you must inform the teaching staff when
turning in your assignment by documenting it in your writeup.
Graded Tasks (100 points total)
In this assignment you are to build a peer-to-peer (p2p) network and
perform a search for an image on the p2p network.
- Implement a peer node similar to the one you
implemented for Lab 2. You may re-use code from Lab 2 (20 points)
- Return multiple known peers, up to a
maximum number (5 pts)
- Automate peer join and redirection (20 points)
- Client image query, adapted from Lab 1.
You may re-use code from Lab 1 (20 points)
- Search for an image (35 points)
- Writeup
Your Tasks
Your first task is to write a peer node. If you've implemented Lab 2
and have decided to build this assignment on top of your working Lab
2, you're done with the first task of this assignment. If you have
not implemented Lab 2, review the support code and
specification of Lab 2. They go into much more details and also
guide you step by step on what needs to be done. In the remainder of this
document I will assume that you are familiar with the Lab 2
specification and support code.
To bootstrap the p2p network, we first start a peer by itself. When
a peer is started without being given another peer to connect to, it
simply creates a socket and listen on it for incoming connections.
Everytime a peer starts, we also have the peer prints to
screen/console its fully qualified domain name (FQDN), and the port
number it is listening on. Subsequent peers are then started with the
FQDN:port of the first peer. Your code must take an optional command
line option "-p <hostname>:<port>"
as in Lab 2. When a peer is given the hostname:port of
another peer at start time, it tries to join that peer in the p2p
network by creating a socket and connecting to the provided peer.
A peer that receives a join request will accept the peer if and only
if its peer table is not full. Whether a join request is accepted or
not, the peer always sends back to the requesting peer the
address and port of at least one peer in its peer table to help
the newly joined peer find more peers to join.
In this assignment, we assume that once a peer joins the network, it
never leaves the network. So you don't have to worry about cleaning
up after departed peer. You must, however, ensure that none of the
peers crash when one of them leave, so you can take down the network
one peer at a time without the others crashing.
In Lab 2, we limit the peer table size of each peer to 2. The command
line option "-n <maxpeer>" allows the user to
specify the peer table size at run time. A study of the Gnutella p2p
network found that half of Gnutella peers supports at most 2
peers. Even though there are peers that support over 130 other peers,
the mean number of peers supported is 5.5. If the -n option
is not specified in the command line, use a default value of
PR_MAXPEERS, which has been bumped up to 6 in the updated
peer.h released with this assignment. If the -n
option is specified, the provided number must be ≥ 1. Given the
small number of peers expected, you can implement the peer table using
a simple table or list with linear insert and/or search times, as is
done in the Lab2 support code. You may, but are not required to, use
STL to implement the peer table. If you use the provided support code
from Lab2, you don't need to do anything to use the larger peering
table other than to swap out the old peer.h with the new one.
We also made the simplifying assumption in Lab2 that the
acknowledgement message sent back to a joining peer contains at most 1
alternate peer. Your next task is to support more than 1 returned peer
with each join acknowledgement message. The acknowledgement message
MUST be of the following format:
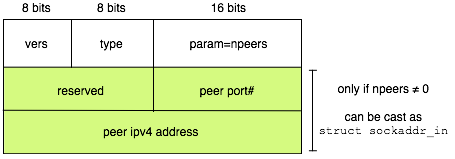 where vers must have the value PM_VERS and
type must be PM_WLCM or PM_RDRT, all as
defined in Lab 2. The field "pm_param" must contain the
exact count of the number of peers returned (starting from 0). The
joining peer MUST NOT be one of the peers returned (you can enforce
this by checking the socket used to connect to each peer). Peer
addresses and port numbers (and reserved field) subsequent to the
first peer simply follow those of the first peer in the byte stream.
So each peer takes up 64 bits on the returned packet (including the
reserved field). The number of peers returned MUST be ≤
PR_MAXPEERS. If your peer table holds more than
PR_MAXPEERS peers, you send only (the first, the last, or
random, your choice) PR_MAXPEERS peers. As in Lab 2, when the
number of peers is 0, the acknowledgement packet MUST consist
only of the first 32 bits of pmsg_t, i.e., without any
peer_t attached. If you're using the Lab2 support code,
you'd need to modify peer::recvmsg() such that its third
argument points to a dynamically allocated array of peer_t
instead of a single peer_t. Don't forget to free the
dynamically allocated memory to avoid memory leak. Building upon
Lab2's peer.cpp, this task should take about 15 lines of
modified and new code.
Note the bolded MUSTs above. Whenever you see a MUST in
a protocol specification, you MUST follow it to the letter, to
ensure that your code can interoperate with other implementations. In
this case, your code must interoperate with the provided reference
implementation, for grading purposes. If your code does not work with
the reference implementation, you will get zero points. Also don't
forget to use ntohs() and htons() wherever
necessary. The reference implementation is provided as
refp2pdb in
/afs/umich.edu/class/eecs489/w16/pa1/. It runs on CAEN
eecs489 hosts (eecs489p1.engin.umich.edu up to p4)
and is a Red Hat 7 binary. Don't try to run it on Debian, Ubuntu, Mac
OS X, or Windows machines, including the ITCS and other CAEN machines.
Remember that you can connect to the CAEN eecs489 hosts only through
UMVPN, MWireless, or
from CAEN Lab desktops.
In Lab 2, when a peer receives a PM_RDRT message, it
simply prints out a join failure/redirection message to the console.
It is then up to the user to re-run the peer to join another peer.
Your third task is to automate this process. When a peer recieves a
PM_RDRT message, instead of simply printing out a
redirection message, your code should go down the list of returned
peers and try to join each one of them until you have filled up your
peer table. Actually, you need to do this even if you receive a
PM_WLCM message if your peer table is not yet full.
If your peer table is full but the list of peers returned to you
by the peer you try to join is not yet exhausted, even if some
peers in the table are still in "pending" state and may end up
rejecting you, you can just throw away the remainder of the list.
If your peer table is still not full after you've exhausted the list
of peers, try to join with peers subsequently referred to you by the
peers you contacted. You need to keep track of four cases: (1) don't
attempt to join peers already in your peer table, (2) don't attempt
another join with peers you already have a pending join, (3) don't
attempt to join the last PR_MAXPEERS peers who have declined
your earlier join attempt, and (4) if you try to join a peer at the
same time it tries to join you, only one of you will successfully form
a link.
The first case is easy to check for: just make sure the peer you want
to join is not already in your peer table. For the second case, if
you enter into your peer table all your pending joins, this case
reduces to the first case. You may want to add a "pending"
field to your peer table entry so that you don't forward a search
packet (see next task) to pending peers. For the third case, you need
to keep a separate "peering declined" table, which MUST be
implemented as a circular array of size PR_MAXPEERS. Prior
to attempting a join, check against this table just like you would
against the peer table. If your join attempt is declined, close the
connection and move the peer from your peer table to your
"peering declined" table. Otherwise, clear the peering
table entry's pending field. The peering declined table should be
used to keep only the most recent PR_MAXPEERS declined, i.e.,
once the table is full, you wrap around and overwrite the first entry.
If your peer table is full, even if some of the entries are still
"pending," don't initiate another join. (This also serves
as a control to make sure that you don't flood the network with join
requests!) As for the fourth case, only one of the two
connect() attempts will succeed. The other will return with
an error and the system errno variable will be set to
EADDRNOTAVAIL. In which case, simply clear the peer table
entry of the failed connection.
If you've exhausted the returned peer lists and you have attempted
a join with all the peers you've heard about and your peer table is
still not full, just chill out, do nothing, and wait for new peers
to connect to you.
Each peer should be identified by only a single address:port
identifier. Thus in connecting to a peer, you want your connect packet
to be assigned the same outgoing IP address and port number as you have
used with all earlier peers.
You may want to modify your
socks_clntinit() to take one more formal argument: a
struct sockaddr_in variable holding the IP address and port
number to use.
If this variable is not NULL, call bind() to bind your connect
socket to the intended IP address and port number before calling
connect().
WARNING: don't confuse yourself by implementing
the peer code as a multi-threaded process. With multithreading, you'd
have to serialize access to the two tables. Just use the
single-threaded event-driven model with select() as in Lab 2.
Then you'll be dealing with only one message at a time and don't have
to worry about inconsistent states caused by multiple messages
arriving at the same time. This task shouldn't take more than
40 modified and new lines of code.
Your next task is to integrate the image query from Lab 1 with the
peering code from Lab 2. If you've implemented Lab 1, you can
re-use your code. If you have not implemented Lab 1, you want to
review its support code and specification to complete this task. The
client, netimg from Lab 1 should work without any modification.
Next, incorporate the server code, imgdb, into the peer code,
which we will then call p2pdb. The server will use two
different ports: one to handle peer-to-peer network maintenance
traffic and another to handle image query traffic. You get the first
when you instantiate a peer object. The second comes with
the instantiation of an imgdb object. We will call the
former the peer socket and the latter the image socket
henceforth. You'd need to register the image socket with
select() along with the peer socket and all the other sockets
connected to other peers. We will use one image socket for both
client query and peer image-search reply (next task).
When a client queries for an image, the server first searches its own
database (or rather, its working directory/folder) for the requested
file name, by calling imgdb::readimg() as in Lab 1. If the
image is found, it is returned to the client and the connection is
then closed. If the client terminates connection part way through the
image transfer, your server should continue to work correctly with
subsequent image queries. If the image is not found, the server
checks whether it is already searching for an image in the
peer-to-peer network on behalf of another client. If so, it returns
an imsg_t packet to the new client with the im_type
field set to NETIMG_EBUSY. That is, a server performs only
one peer-to-peer search at any one time. You have to decide how to
determine that a server is already serving another client. We will
discuss how to handle peer-to-peer search in the next task.
At this point, you should test your code and verify that your
netimg client and p2pdb server work as in Lab 1 to
serve up image files that are local to the server. To build the
client, you'll need the files netimg.cpp,
netimglut.cpp, netimg.h, socks.cpp, and
socks.h. To build the server/peer, you'll need all the
provided files except netimg.cpp and netimglut.cpp.
See the provided Makefile. On Windows, you'll additionally
need wingetopt.c and wingetopt.h. This task should
take about 12 lines of modified or new code in peer.cpp and
imgdb.cpp. You'll need to comment out the main()
function in imgdb.cpp.
When a peer cannot find an image locally, it sends out a search packet
through the peer-to-peer network. When a queried image is found, the
peer holding the image connects directly with the peer searching for
the image (originating peer) and transfers the image to the
originating peer, who then forwards it to the client. As explained in
the previous section, this connection is made to the originating
peer's image socket. Thus the search packet must carry the
originating peer's address and its image socket's port number, along
with the name of the image being searched for. You may re-use code
from Lab 2 for this task. The query/search packet MUST follow
this format:
where vers must have the value PM_VERS and
type must be PM_WLCM or PM_RDRT, all as
defined in Lab 2. The field "pm_param" must contain the
exact count of the number of peers returned (starting from 0). The
joining peer MUST NOT be one of the peers returned (you can enforce
this by checking the socket used to connect to each peer). Peer
addresses and port numbers (and reserved field) subsequent to the
first peer simply follow those of the first peer in the byte stream.
So each peer takes up 64 bits on the returned packet (including the
reserved field). The number of peers returned MUST be ≤
PR_MAXPEERS. If your peer table holds more than
PR_MAXPEERS peers, you send only (the first, the last, or
random, your choice) PR_MAXPEERS peers. As in Lab 2, when the
number of peers is 0, the acknowledgement packet MUST consist
only of the first 32 bits of pmsg_t, i.e., without any
peer_t attached. If you're using the Lab2 support code,
you'd need to modify peer::recvmsg() such that its third
argument points to a dynamically allocated array of peer_t
instead of a single peer_t. Don't forget to free the
dynamically allocated memory to avoid memory leak. Building upon
Lab2's peer.cpp, this task should take about 15 lines of
modified and new code.
Note the bolded MUSTs above. Whenever you see a MUST in
a protocol specification, you MUST follow it to the letter, to
ensure that your code can interoperate with other implementations. In
this case, your code must interoperate with the provided reference
implementation, for grading purposes. If your code does not work with
the reference implementation, you will get zero points. Also don't
forget to use ntohs() and htons() wherever
necessary. The reference implementation is provided as
refp2pdb in
/afs/umich.edu/class/eecs489/w16/pa1/. It runs on CAEN
eecs489 hosts (eecs489p1.engin.umich.edu up to p4)
and is a Red Hat 7 binary. Don't try to run it on Debian, Ubuntu, Mac
OS X, or Windows machines, including the ITCS and other CAEN machines.
Remember that you can connect to the CAEN eecs489 hosts only through
UMVPN, MWireless, or
from CAEN Lab desktops.
In Lab 2, when a peer receives a PM_RDRT message, it
simply prints out a join failure/redirection message to the console.
It is then up to the user to re-run the peer to join another peer.
Your third task is to automate this process. When a peer recieves a
PM_RDRT message, instead of simply printing out a
redirection message, your code should go down the list of returned
peers and try to join each one of them until you have filled up your
peer table. Actually, you need to do this even if you receive a
PM_WLCM message if your peer table is not yet full.
If your peer table is full but the list of peers returned to you
by the peer you try to join is not yet exhausted, even if some
peers in the table are still in "pending" state and may end up
rejecting you, you can just throw away the remainder of the list.
If your peer table is still not full after you've exhausted the list
of peers, try to join with peers subsequently referred to you by the
peers you contacted. You need to keep track of four cases: (1) don't
attempt to join peers already in your peer table, (2) don't attempt
another join with peers you already have a pending join, (3) don't
attempt to join the last PR_MAXPEERS peers who have declined
your earlier join attempt, and (4) if you try to join a peer at the
same time it tries to join you, only one of you will successfully form
a link.
The first case is easy to check for: just make sure the peer you want
to join is not already in your peer table. For the second case, if
you enter into your peer table all your pending joins, this case
reduces to the first case. You may want to add a "pending"
field to your peer table entry so that you don't forward a search
packet (see next task) to pending peers. For the third case, you need
to keep a separate "peering declined" table, which MUST be
implemented as a circular array of size PR_MAXPEERS. Prior
to attempting a join, check against this table just like you would
against the peer table. If your join attempt is declined, close the
connection and move the peer from your peer table to your
"peering declined" table. Otherwise, clear the peering
table entry's pending field. The peering declined table should be
used to keep only the most recent PR_MAXPEERS declined, i.e.,
once the table is full, you wrap around and overwrite the first entry.
If your peer table is full, even if some of the entries are still
"pending," don't initiate another join. (This also serves
as a control to make sure that you don't flood the network with join
requests!) As for the fourth case, only one of the two
connect() attempts will succeed. The other will return with
an error and the system errno variable will be set to
EADDRNOTAVAIL. In which case, simply clear the peer table
entry of the failed connection.
If you've exhausted the returned peer lists and you have attempted
a join with all the peers you've heard about and your peer table is
still not full, just chill out, do nothing, and wait for new peers
to connect to you.
Each peer should be identified by only a single address:port
identifier. Thus in connecting to a peer, you want your connect packet
to be assigned the same outgoing IP address and port number as you have
used with all earlier peers.
You may want to modify your
socks_clntinit() to take one more formal argument: a
struct sockaddr_in variable holding the IP address and port
number to use.
If this variable is not NULL, call bind() to bind your connect
socket to the intended IP address and port number before calling
connect().
WARNING: don't confuse yourself by implementing
the peer code as a multi-threaded process. With multithreading, you'd
have to serialize access to the two tables. Just use the
single-threaded event-driven model with select() as in Lab 2.
Then you'll be dealing with only one message at a time and don't have
to worry about inconsistent states caused by multiple messages
arriving at the same time. This task shouldn't take more than
40 modified and new lines of code.
Your next task is to integrate the image query from Lab 1 with the
peering code from Lab 2. If you've implemented Lab 1, you can
re-use your code. If you have not implemented Lab 1, you want to
review its support code and specification to complete this task. The
client, netimg from Lab 1 should work without any modification.
Next, incorporate the server code, imgdb, into the peer code,
which we will then call p2pdb. The server will use two
different ports: one to handle peer-to-peer network maintenance
traffic and another to handle image query traffic. You get the first
when you instantiate a peer object. The second comes with
the instantiation of an imgdb object. We will call the
former the peer socket and the latter the image socket
henceforth. You'd need to register the image socket with
select() along with the peer socket and all the other sockets
connected to other peers. We will use one image socket for both
client query and peer image-search reply (next task).
When a client queries for an image, the server first searches its own
database (or rather, its working directory/folder) for the requested
file name, by calling imgdb::readimg() as in Lab 1. If the
image is found, it is returned to the client and the connection is
then closed. If the client terminates connection part way through the
image transfer, your server should continue to work correctly with
subsequent image queries. If the image is not found, the server
checks whether it is already searching for an image in the
peer-to-peer network on behalf of another client. If so, it returns
an imsg_t packet to the new client with the im_type
field set to NETIMG_EBUSY. That is, a server performs only
one peer-to-peer search at any one time. You have to decide how to
determine that a server is already serving another client. We will
discuss how to handle peer-to-peer search in the next task.
At this point, you should test your code and verify that your
netimg client and p2pdb server work as in Lab 1 to
serve up image files that are local to the server. To build the
client, you'll need the files netimg.cpp,
netimglut.cpp, netimg.h, socks.cpp, and
socks.h. To build the server/peer, you'll need all the
provided files except netimg.cpp and netimglut.cpp.
See the provided Makefile. On Windows, you'll additionally
need wingetopt.c and wingetopt.h. This task should
take about 12 lines of modified or new code in peer.cpp and
imgdb.cpp. You'll need to comment out the main()
function in imgdb.cpp.
When a peer cannot find an image locally, it sends out a search packet
through the peer-to-peer network. When a queried image is found, the
peer holding the image connects directly with the peer searching for
the image (originating peer) and transfers the image to the
originating peer, who then forwards it to the client. As explained in
the previous section, this connection is made to the originating
peer's image socket. Thus the search packet must carry the
originating peer's address and its image socket's port number, along
with the name of the image being searched for. You may re-use code
from Lab 2 for this task. The query/search packet MUST follow
this format:
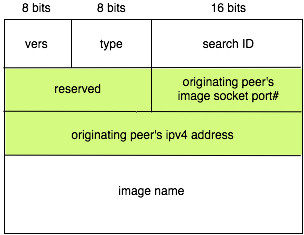 where vers MUST be PM_VERS as before,
type MUST be PM_SRCH. The "search
ID" field is a way for you to differentiate subsequent searches
for the same image name from the same originating peer (see below).
It can be a simple monotonically increasing number at each peer,
incremented for each search. You don't have to worry about the number
wrapping around in this assignment. The port number in the search
message is that of the image socket, NOT the peer
socket. The search packet definition is provided to you in the
support code file search.h. Since a search query has to be
communicated between a peer object and an imgdb
object, you may want to include this header file in both object
definition source files. The updated peer.h does this
already. Don't forget to use htons() and ntohs() as
necessary. The peer initiating an image search sends a copy of this
search packet to all the peers in its peer table.
Search packets are sent along the connections made between peers,
i.e., the "links" forming the p2p network. Peering
relationships that are still "pending" (see the
"Automatic Join" section above), should not be used to
forward search packet. Once you have sent out a search packet to all
your connected peers, you don't need to send it again if new peers
connect to you at a later time. When a search packet arrives at a
peer, the peer must check whether it has seen the same query
previously. You don't have to keep a very long history. Just keep
the last PR_MAXPEERS number of the most recent searches and
check against them. Again, you MUST keep these in a circular array.
If the peer has seen the search in the recent past, it simply drops
the packet. Otherwise, it checks whether it has a copy of the queried
image (by calling imgdb::readimg()). If it does not have a
copy of the image, the peer forwards the query further to all its
peers, except the peer whence the query arrived. Your code must be
able to make these determinations and not forward the search packet in
the three cases mentioned here: (1) pending join, (2) previously seen
search, and (3) the peer whence the search message arrived. You
will be deducted points if your queries loop on your p2p
network because your node doesn't drop duplicate queries.
If a peer has no other peer to forward a search query, it simply drops
the query. If a peer has a copy of the queried image, it creates a
new socket and connects to the query originating peer at the address
and port number listed in the search packet. Thus the image is not
transmitted on the "links" of the p2p network, but on a
separate connection directly to the query originating peer, created
just to transfer the image. To transfer the image, first send to the
originating peer an imsg_t packet with the image dimension
by calling imgdb::marshall_imsg() and imgdb::sendimsg().
The im_type field of the imsg_t packet must be set to
NETIMG_FOUND. Once the image transfer is completed, the
connection is closed by the peer initiating the transfer. The
originating peer then forwards the image to the client requesting it
and closes the connection to the client. If the originating peer
receives multiple copies of the requested image, it only returns one
copy to the client. If it receives an image when it is not waiting
for any search reply, it can simply closes the connection with the
peer. At any one time, a peer can only perform a search on
behalf of one client. Your code should enforce this.
If a reply for an old search arrives after a new client initiated a
new search, the peer will return the wrong image to the new client.
Your code is not required to handle this error case.
Image transfer between peers and between a peer and its client
MUST follow the same protocol as in Lab 1: you MUST precede the image
with an imsg_t packet.
where vers MUST be PM_VERS as before,
type MUST be PM_SRCH. The "search
ID" field is a way for you to differentiate subsequent searches
for the same image name from the same originating peer (see below).
It can be a simple monotonically increasing number at each peer,
incremented for each search. You don't have to worry about the number
wrapping around in this assignment. The port number in the search
message is that of the image socket, NOT the peer
socket. The search packet definition is provided to you in the
support code file search.h. Since a search query has to be
communicated between a peer object and an imgdb
object, you may want to include this header file in both object
definition source files. The updated peer.h does this
already. Don't forget to use htons() and ntohs() as
necessary. The peer initiating an image search sends a copy of this
search packet to all the peers in its peer table.
Search packets are sent along the connections made between peers,
i.e., the "links" forming the p2p network. Peering
relationships that are still "pending" (see the
"Automatic Join" section above), should not be used to
forward search packet. Once you have sent out a search packet to all
your connected peers, you don't need to send it again if new peers
connect to you at a later time. When a search packet arrives at a
peer, the peer must check whether it has seen the same query
previously. You don't have to keep a very long history. Just keep
the last PR_MAXPEERS number of the most recent searches and
check against them. Again, you MUST keep these in a circular array.
If the peer has seen the search in the recent past, it simply drops
the packet. Otherwise, it checks whether it has a copy of the queried
image (by calling imgdb::readimg()). If it does not have a
copy of the image, the peer forwards the query further to all its
peers, except the peer whence the query arrived. Your code must be
able to make these determinations and not forward the search packet in
the three cases mentioned here: (1) pending join, (2) previously seen
search, and (3) the peer whence the search message arrived. You
will be deducted points if your queries loop on your p2p
network because your node doesn't drop duplicate queries.
If a peer has no other peer to forward a search query, it simply drops
the query. If a peer has a copy of the queried image, it creates a
new socket and connects to the query originating peer at the address
and port number listed in the search packet. Thus the image is not
transmitted on the "links" of the p2p network, but on a
separate connection directly to the query originating peer, created
just to transfer the image. To transfer the image, first send to the
originating peer an imsg_t packet with the image dimension
by calling imgdb::marshall_imsg() and imgdb::sendimsg().
The im_type field of the imsg_t packet must be set to
NETIMG_FOUND. Once the image transfer is completed, the
connection is closed by the peer initiating the transfer. The
originating peer then forwards the image to the client requesting it
and closes the connection to the client. If the originating peer
receives multiple copies of the requested image, it only returns one
copy to the client. If it receives an image when it is not waiting
for any search reply, it can simply closes the connection with the
peer. At any one time, a peer can only perform a search on
behalf of one client. Your code should enforce this.
If a reply for an old search arrives after a new client initiated a
new search, the peer will return the wrong image to the new client.
Your code is not required to handle this error case.
Image transfer between peers and between a peer and its client
MUST follow the same protocol as in Lab 1: you MUST precede the image
with an imsg_t packet.
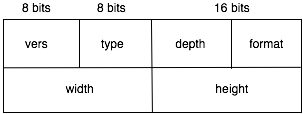 The type field must be set to NETIMG_FOUND. You can
use imgdb::sendimsg() and imgdb::sendimg() to
perform all image transfers. See how these functions are used
imgdb::handleqry() for an example. Image transfer between
peers should be done fast, as one segment.
Since a search may fail to find the queried image, the querying peer
must set a timer, as the last argument to select(). If the
timer expires without any reply from another peer, it gives up waiting
for a reply, informs the client that the image could not be found, and
closes the connection to the client. You can use 1 second timeout
value. Since the timeout can be interrupted by activities in the
other sockets you're selecting on, you'd normally compute how much
time has passed and reset the timeout to the smaller time value in
your subsequent call to select(). To keep things simpler for
you, you can continue to use 1 second timeout on each call to
select(), without decrementing it. Your peer-to-peer network
is not so busy that this would lead to indefinite timeout.
Notice that on the peer socket, a peer could receive either a join
acknowledgement packet or an image search packet. While on the image
socket, a peer could receive either a client query packet
(iqry_t) or a search reply packet (imsg_t). The
common denominator for all these packet types are the first two bytes.
You can either grab the first two bytes of a packet off the socket
receive queue or you could use the MSG_PEEK flag with the
socket recv() API to look at the first two bytes without
removing them from the receive queue. You can then decide how to
receive the rest of the packet based on the type encoded in the second
byte of the packet. Don't forget to check that the packet is of the
expected version number. If a packet with the wrong version number is
received, call socks_clear() as in Lab 2 to clear the receive
queue of all bits currently sitting in the queue and then resume to
receive new data. In particular, if a search packet with the wrong
version number is received (set using the -v <version>
command line option), your peer implementation must clear the packet
off its receive queue without forwarding or serving the query and must
then be able to handle subsequent search packets correctly. If you
use the support code from Labs 1 and 2, feel free to modify the
object method prototypes as necessary.
This task takes about 100 to 105 lines of modified and new code.
The type field must be set to NETIMG_FOUND. You can
use imgdb::sendimsg() and imgdb::sendimg() to
perform all image transfers. See how these functions are used
imgdb::handleqry() for an example. Image transfer between
peers should be done fast, as one segment.
Since a search may fail to find the queried image, the querying peer
must set a timer, as the last argument to select(). If the
timer expires without any reply from another peer, it gives up waiting
for a reply, informs the client that the image could not be found, and
closes the connection to the client. You can use 1 second timeout
value. Since the timeout can be interrupted by activities in the
other sockets you're selecting on, you'd normally compute how much
time has passed and reset the timeout to the smaller time value in
your subsequent call to select(). To keep things simpler for
you, you can continue to use 1 second timeout on each call to
select(), without decrementing it. Your peer-to-peer network
is not so busy that this would lead to indefinite timeout.
Notice that on the peer socket, a peer could receive either a join
acknowledgement packet or an image search packet. While on the image
socket, a peer could receive either a client query packet
(iqry_t) or a search reply packet (imsg_t). The
common denominator for all these packet types are the first two bytes.
You can either grab the first two bytes of a packet off the socket
receive queue or you could use the MSG_PEEK flag with the
socket recv() API to look at the first two bytes without
removing them from the receive queue. You can then decide how to
receive the rest of the packet based on the type encoded in the second
byte of the packet. Don't forget to check that the packet is of the
expected version number. If a packet with the wrong version number is
received, call socks_clear() as in Lab 2 to clear the receive
queue of all bits currently sitting in the queue and then resume to
receive new data. In particular, if a search packet with the wrong
version number is received (set using the -v <version>
command line option), your peer implementation must clear the packet
off its receive queue without forwarding or serving the query and must
then be able to handle subsequent search packets correctly. If you
use the support code from Labs 1 and 2, feel free to modify the
object method prototypes as necessary.
This task takes about 100 to 105 lines of modified and new code.
Testing Your Code
You will be graded for correctness primarily by running your program
on a number of test cases. If you have a single silly bug that causes
most of the test cases to fail, you will get a very low score on that
part of the programming assignment even if you completed 95% of
the work. Most of your grade will come from correctness testing.
Therefore, it is imperative that you test your code thoroughly. Each
testcase should test only one particular feature of your program.
Just as professional software firms do not ask for testcases from
their customers prior to releasing their code, it is your
responsibility to test your code thoroughly and not rely on the
teaching staff to provide test cases.
Here's a scenario to test your p2p network construction code using
four hosts. At the first host, start your peer code with max peers
set to 2. Next start a second peer with max peer set to 3, connect it
to the first peer. Then start a third peer with max peer set to 2 and
connect it to the second peer. If your automatic join code is
working, peer 3 should then also join peer 1. Finally, start peer 4
with max peer set to 1 and try to connect it to peer 3. Peer 4 should
fail to connect to peers 3 and 1 but successfully connect to peer
2.
To test your search code, search for an image that is at least
2 hops away. Search for a non-existing image, and search for an image
that is held by more than one peers.
To test your correct handling of the search version number, let one of
your peer, for example the third peer in the above test case, set the
wrong version number in all of its search packets and observe how the
other peers handle the wrong version number and whether they continue
to function correctly afterwards. You may want to test wrong version
number handling for search and acknowledgement packets separately.
The error and diagnostic messages your code print out on console
do not have to match those of the reference implementation
exactly. We're not relying on an autograder to grade your implementation.
Nevertheless, do be careful that your error and diagnostic messages
are meaningful and not overwhelming. For example, if your code spew
out a huge amount of messages that scroll off the screen without
us being able to make head or tail of it, you could get very low grade.
See the note below about debugging messages. One simple rule of thumb
is to retain error and diagnostic messages that inform users of the
correct working of your code but to remove all debugging messages
intended only for yourself (such as "got here" or "in socks_clntinit",
please try avoid obscene messages and comments).
Support Code
The support code for Labs 1 and 2 form most of the support code of this
assignment. Additional support code consisting of an
updated Makefile that builds both netimg and
p2pdb, an updated peer.h, and a search.h
containing the definition of a search packet is available for download.
So that you don't feel like you're only filling in
functions and not having any chance to write your own program from
scratch, we are not providing further support code beyond the above.
If you have not been able to complete Lab 1 and would
like the solution so that you can complete this assignment, you may
choose to forfeit the 20 points associated with it and obtain a
solution from us. Similarly for Lab 2. Sharing the provided code
and solutions is considered cheating and will be reported to the
Honor Council.
Submission Instructions
Your solution must either work with the provided Makefile or
you must provide a Makefile that works on CAEN eecs489
hosts. Do NOT use any library or compiler
option that is not used in the provided Makefile.
Doing so would likely make your code not portable and if we can't
compile your code, you will be heavily penalized. Test
your compilation on CAEN eecs489 hosts! Your submission must
compile and run without errors on CAEN eecs489 hosts.
Your code MUST be interoperable with the
provided refp2pdb in the Course Folder.
Create a writeup in text format that discusses:
- Your platform and its
version -
Linux, Mac OS X, or Windows, and which version and flavor of each.
- Anything about your implementation that is noteworthy.
- Feedback on the assignment.
- Name the file writeup-uniqname.txt.
For example, the person with uniqname
skywalker would create
writeup-skywalker.txt.
Your PA1 files comprises your
writeup-uniqname.txt and your source code files
for both your p2pdb and netimg.
To turn in your PA1, upload a zipped or
gzipped tarball of your
PA1 files to the CTools Drop Box. Keep your own
backup copy! The timestamp on your uploaded file is your time
of submission. If this is past the deadline, your submission will be
considered late. You are allowed multiple "submissions"
without late-policy implications as long as you respect the deadline.
We highly recommend that you use a private
third party repository such as github or M+Box or Dropbox to keep the
back up copy of your submission. Local timestamps can be easily
altered and cannot be used to establish your files' last modification
times (-10 points). Be careful to use only
third-party repository that allows for private access.
To put your code in publicly accessible third-party
repository is an Honor Code violation.
Turn in ONLY the files you have modified. Do
not turn in support code we provided that you haven't modified (-4 points).
Do not turn in any binary files (object, executable, dll,
library, or image files) with your assignment (-4 points). Your code
must not require other compiler options, external libraries, or
header files other than the ones listed in the Makefile
(-10 points).
Do remove all printf()'s or
cout's and cerr's and any other logging statements
you've added for debugging purposes. You should debug using a
debugger, not with printf()'s. If we can't understand the
output of your code, you will get zero point.
General
It is part of the Honor Code of this course that the overall design
and final details and implementation of your programming assignments
must be your own. If you're stuck in either the design,
implementation, or debugging of the assignment, you're allowed and
encouraged to consult with your classmates. However, the original
design and final implementation details must all be your own. So you
cannot come up with the original design together with your
classmates. You can consult your classmates only after you've
come up with your own design but ran into some specific problems.
Similarly for the implementation, you cannot consult your classmates
prior to writing your own implementation. And in all cases, you're
not allowed to look at any of your classmates' source code, not even
in order to help them to debug. The same applies to design and
implementation from previous terms.
Coding style
- Use a reasonable organization for your overall program:
- Design a fairly reasonable class structure. On the one hand,
don't stick everything into one class/struct. On the other hand, don't be
bureaucratic and require the reader to follow one class definition
after another to find a single line of code wrapped in n layers of
methods, with each method doing nothing but calling the next one.
If the way you design your code feels sloppy to you, it
probably is. Utilize multiple files in a way that is consistent with
the general use of C/C++. Don't use more files than necessary, you don't
have to put each class/struct in a separate file of its own.
Don't use literals!
- Use either
const, enum, or #define
to give your literals meaningful names.
#define ONE 1
const ZERO=0;
would be examples of names that are no different than using literals
and would be treated as equivalent to using literals.
We do deduct points for each occurrence of literals or
equivalently literal names, even if it is the same one. The only
exceptions will be for loop counter, command-line options,
NULL(0) and TRUE/FALSE(1/0) testing/setting, and help and error
messages printed out to user, and mathematically well-defined uses
such as (1-probability) or to test for negativite values (< 0), etc.
The intent here is to ensure that should the literal value need to be
changed in the future, it only needs to be changed in one place. Thus
defining '0' as "ZERO" does not serve this purpose because should
the value '0' need to be changed in the future, the macro "ZERO"
becomes totally misleading. We will thus deduct points for such
semantically meaningless names also.
Use reasonable comments: - Explain what each class does and what each data member is used
for. A one or two line description of most member functions is also
desirable. Where you use non-standard coding techniques, document them.
List your name and the date last modified for each file.
-
- Remember that a useless comment is worse than no comment at all.
int temp; // declare temp. variable
would be an example of a useless comment which just makes code harder
to read!
Use reasonable formatting:
- From indentation alone, it should be obvious where a given code
block ends. Avoid lines that wrap in an 80 column display wherever
possible. Your code should be tight, compact, and visually tidy. Don't
let bits and pieces fly off every which way. Your code is not abstract
painting.
Variable names:
- Use reasonable and informative variable names, but limit name
size to a reasonable length. A 40-character name better has a very good
reason to exist. Variable names like 'i' and 'j' can be reasonable, but
you should not use such variables to store meaningful long-term data.
Other than LCV (loop control variables) you should use descriptive
names for your variables, functions, classes, methods, structures, etc.
Reduce, Reuse, and Recycle your code, algorithms, and structures:
- Try using inheritance, templating, polymorphism (virtual
function), or similar methods to reduce the size of your code. Do not
unnecessarily duplicate code. Less code leads to less debugging. If you
find yourself rewriting basically the same code more than once, stop
and try to see if you can somehow reuse the code by making it a
function call or implementing a polymorphic function.
Unreadable code can cost you up to
10 points!
Empirical efficiency
We will check for empirical efficiency both by measuring the memory
usage and running time of your code and by reading the code. We will
focus on whether you use unnecessary temporary variables, whether you
copy data when a simply reference to it will do, whether you use an
O(n) algorithm or an O(n^2) algorithm, but not whether you use
printf's or fprintf's. Nor whether your ADTs
have the cleanest interfaces. In general, if the tradeoff is between
illegible and fast code vs. pleasant to read code that is unnoticeably
less efficient, we will prefer the latter. (Of course pleasant to read
code that is also efficient would be best.) However, take heed what you
put in your code. You should be able to account for every class, method,
function, statement, down to every character you put in your code.
Why is it there? Is it necessary to be there? Can you do without?
Perfection is reached not when there is nothing more to add, but when
there is nothing more that can be taken away, someone once said.
Okay, that may be a bit extreme, but do try to mind how you express
yourself in code.
Hints and advice
If any part of this document is unclear, ambiguous,
contradictory, or just plain wrong, please let one of the teaching staff know. Have fun coding!