|
In developing scc, we show how to systematically exploit
storage diversity, i.e, select among different physical media,
local and remote storage, and various caching strategies.
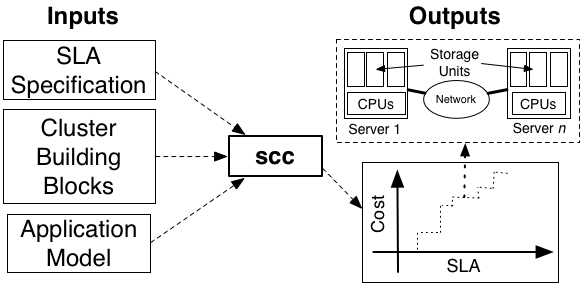
As shown in the adjacent figure, scc takes three inputs: i) a model of
application behavior, specified in part
by the application's developer and in part by the
administrator deploying the application, ii) characteristics
of available hardware building blocks specified by the
infrastructure provider, and iii) application performance
metrics, i.e., a parameterized service level agreement (SLA)
(e.g., a webservice SLA might specify a peak query rate per
second). Given these inputs, scc computes how cluster cost
varies as a function of the SLA and outputs a low-cost cluster
configuration that meets the SLA at each point in the space.
scc's output cost vs. SLA value distribution helps
administrators decide what performance can be supported cost
effectively.
|