From Lifestyle VLOGs to Everyday Interactions:
The VLOG Dataset

|
What on earth is a Lifestyle VLOG and where does this data come from?
Lifestyle VLOGs are an immensely popular genre of video that people publicly upload to Youtube to document their lives (an archetypical example that appears in VLOG is here). The actual story is perhaps more complicated, as described very well by Roisin Kiberd here: the overall plotline of the video is generally aspirational (out of bed at 7am, cup of black coffee, cute fluffy dog). Nonetheless, the individual components (getting out of bed, pouring a cup of coffee) are accurate.
Why is this sort of data of interest to computer vision?
Attempts to understand daily behavior have been constrained for a long time by a lack of good data. The basic problem is that computer vision has so far taken an explicit approach to getting data: starting with a laundry list of categories, searching for each on the Internet. This runs into trouble because everyday interactions are unlikely to be tagged on the Internet. For example, who uploads and tags a video of themselves: opening a microwave, opening a fridge, or getting out of bed?
This has led people to focus on easy-to-find actions that are likely to be tagged -- for example, jumping in a pool, presenting the weather, or playing the harp. Unfortunately, these easy-to-find things are unusual (hence the tags).
Moreover, even if we can find data by searching this way, the results tend to be atypical. Google image search results for even basic concepts are highly biased: almost all results for bedroom are clearly staged and depict a made bed from 2-3 meters away; nearly all results for kitchen depict clean kitchens with no obstructions on the counter. Our paper shows some practical consequences of this: methods trained on images taken of bedrooms tend not to work well on images taken in bedrooms.
What's the solution?
We believe the solution to these problems is to search implicitly: we start out with a superset of what we want, namely interaction-rich video data, and then annotate and analyze it after the fact. We have used this idea, along with Lifestyle VLOGs, to collect VLOG, a dataset we are freely sharing with the community. Paradoxically, we have found that this implicit approach is actually far more effective at finding things than directly going out and trying to find them.
Paper
Video datasets are best watched: Supplemental Video

|
From Lifestyle VLOGs to Everyday interaction D.F. Fouhey, W. Kuo, A.A. Efros, J. Malik CVPR 2018 [Show BibTex] |
About the dataset
VLOG is part of a growing ecosystem of datasets aimed at understanding everyday human interaction, each of which has complementary strengths. We compare our data on a number of fronts in the paper. One salient aspect for VLOG is scale in terms of sheer volume and participants -- by virtue of its implicit gathering approach, VLOG is clearly large, but importantly, comes from a far larger number of subjects.
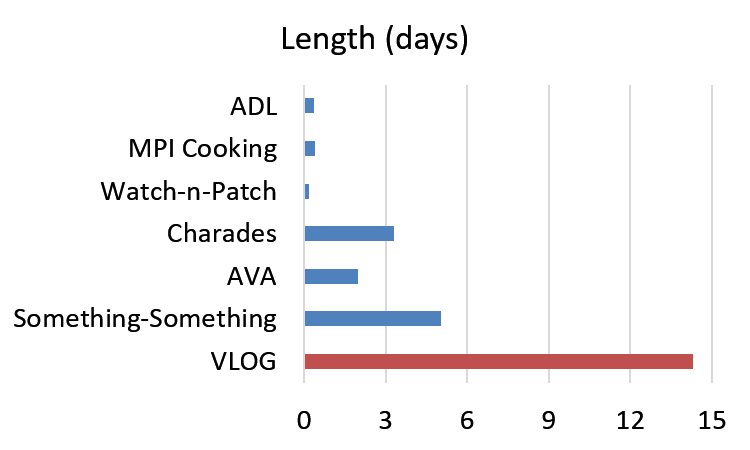 | 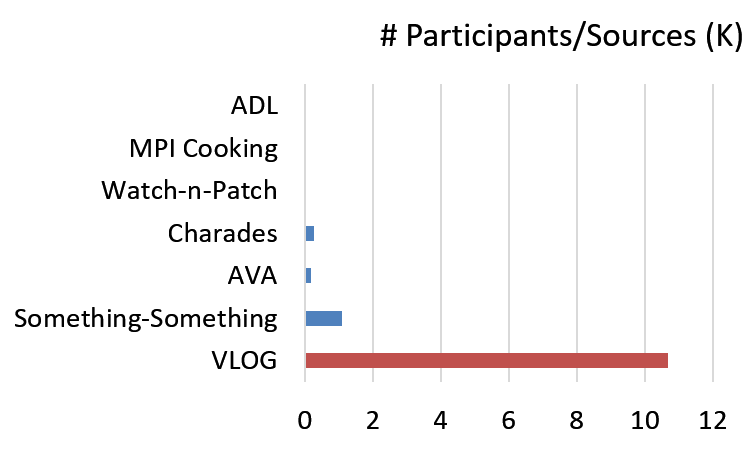 |
- ADL (Pirsiavash et al. 2012)
- MPI Cooking (Rohrbach et al. 2012)
- GTEA (Fathi et al. 2012)
- CAD-120 (Koppula et al. 2013)
- Watch-n-Patch (Wu et al. 2015)
- Instructions (Alayrac et al. 2016)
- Charades (Sigurdsson et al. 2016)
- AVA (Gu et al. 2017)
- Something-Something (Goyal et al. 2017)
Dataset
We are distributing VLOG via a file, data_v1.1.tgz, containing:
- Clips in terms of the publicly available youtube id and frame start and end.
- Labels (v1.1). Depending on community interest, we may obtain additional annotations.
- Split information and uploader id.
- Precomputed results for methods reported in the paper and other ones requested by reviewers.
Code
We are distributing code for evaluation and loading on github.
Cached Copies
We do not hold the copyright to these videos, but to avoid the tedium of downloading and processing the data, we are making available our local copy of the data for non-commercial research purposes only. Click here to download our copies.
Q&A
Q. Google drive is so painful! How can avoid this?
A. We tried a few options and it was the one that provided sufficiently reliable service without breaking our bank. Try skicka if you'd like to download it on a remote server.
Q. I found what I think is a labeling mistake or something objectionable.
A. Please email David with any issues. This dataset is enormous, and we have done our best to provide accurate labels on high quality data but are committed to making the dataset as good as possible. We may release updated and additional labels and would love to fix any issues that you come across.
Q. What about full resolution?
A. This is coming. It's enormous and so we're looking for ways to distribute it.
Acknowledgements
This work was supported in part by Intel/NSF VEC award IIS-1539099. We gratefully acknowledge NVIDIA corporation for the donation of GPUs used for this research. DF thanks David Forsyth, Saurabh Gupta, Phillip Isola, Andrew Owens, Abhinav Shrivastava, and Shubham Tulsiani for advice throughout the process.