Emily Mower Provost
Associate Professor, Computer Science and Engineering


Emily Mower Provost
Associate Professor, Computer Science and Engineering
Associate Professor, Computer Science and Engineering
Associate Professor, Computer Science and Engineering

Associate Professor
University of Michigan
EECS Department
Computer Science & Engineering
3629 BBB
Ann Arbor, MI 48109-2121
Tel: 734-647-1802
Email:

Computational Human Artificial Intelligence (CHAI) Lab
Emotion is central to communication; it colors our interpretation of events and social interactions. Emotion expression is generally multimodal, modulating our facial movement, vocal behavior, and body gestures. The method through which this multimodal information is integrated and perceived is not well understood. This knowledge has implications for the design of multimodal classification algorithms, affective interfaces, and even mental health assessment. We present a novel data set designed to support research into the emotion perception process, the University of Michigan Emotional McGurk Effect Data set (UMEME). UMEME has a critical feature that differentiates it from currently existing data sets; it contains not only emotionally congruent stimuli (emotionally matched faces and voices), but also emotionally incongruent stimuli (emotionally mismatched faces and voices). The inclusion of emotionally complex and dynamic stimuli provides an opportunity to study how individuals make assessments of emotion content in the presence of emotional incongruence, or emotional noise. We describe the collection, annotation, and statistical properties of the data and present evidence illustrating how audio and video interact to result in specific types of emotion perception. The results demonstrate that there exist consistent patterns underlying emotion evaluation, even given incongruence, positioning UMEME as an important new tool for understanding emotion perception (NSF IIS: 1217104).
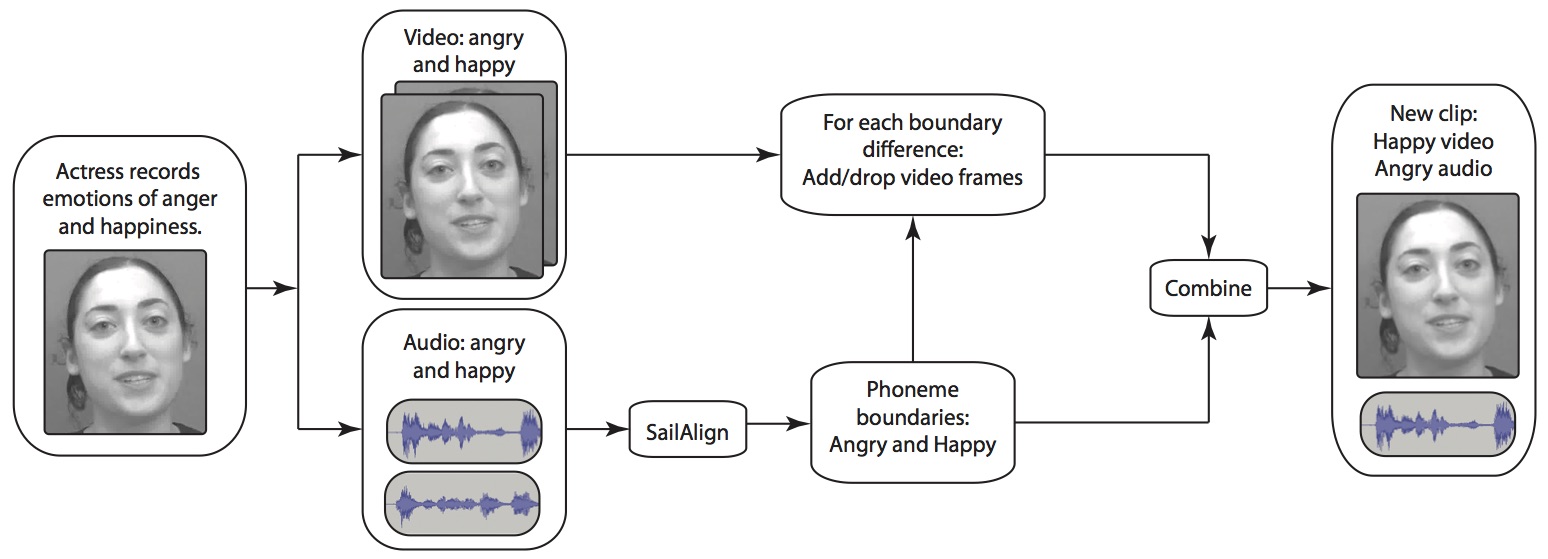
The dataset was created using the MSP-Improv stimuli (link), collected by Carlos Busso at UT Dallas. MSP-Improv is an acted audio-visual emotion corpus. The recording paradigm was designed to maximize the naturalness of the data, while still providing the fixed lexical content needed for the creation of the stimuli. We designed 20 sentences of variable length. These sentences were embedded within emotional dialogs (i.e., angry, happy, neutral, and sad), which led to each sentence being repeated in each of the four emotions.
We created unimodal stimuli from the multimodal data by stripping out the audio and the video components of the data. This led to three stimuli sets:
We used the AO stimuli to find the phoneme-level timing in sentences with the same lexical content, in each of the four emotion classes. We used differences between the phoneme timing to warp the VO stimuli. The audio and time-aligned video stimuli were recombined. This resulted in two new stimuli sets:
The dataset will be released to the community in the near future.
This material is based upon work supported by the National Science Foundation under Grant IIS-1217104. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Emily Mower Provost, Yuan (June) Shangguan, Carlos Busso, "UMEME: University of Michigan Emotional McGurk Effect Dataset," IEEE Transactions of Affective Computing, 10:1(395-409), 2015. [pdf]