SDM 2017 Tutorial
Summarizing Large-Scale Graph Data:
Algorithms, Applications & Open Challenges
Danai Koutra, Computer Science and Engineering, University of Michigan
Abstract
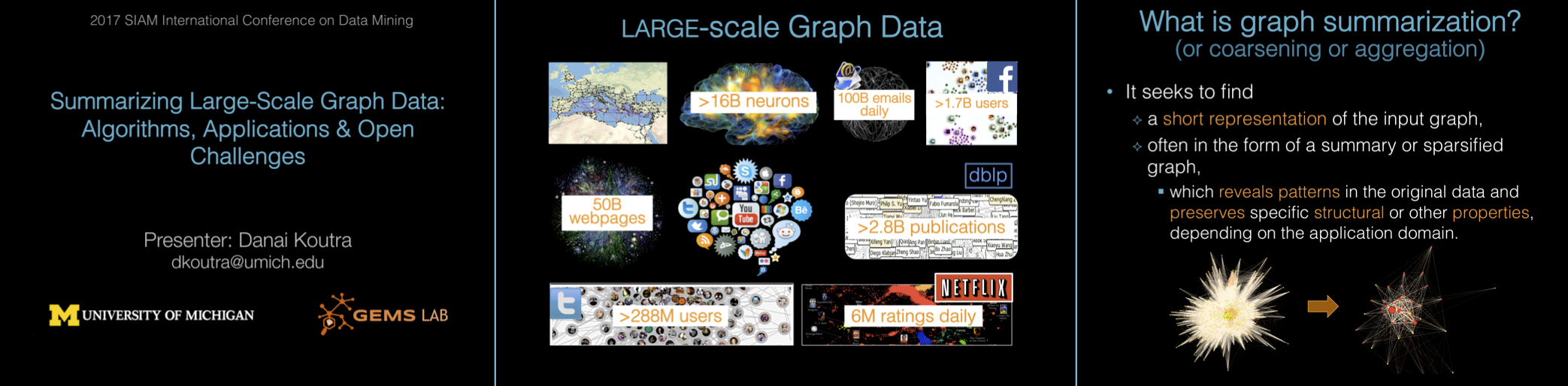
 Recent advances in computing resources have made possible collecting enormous amounts of data, such as social media interactions, web browsing, product and service purchases, autonomous vehicle routing, activities via smart home sensors and health / wellness sensors, and more. Since summarization helps humans find structure and meaning in data, the data mining community has taken a strong interest in the task and accordingly has proposed many methods for a variety of data types. This tutorial aims to provide a comprehensive overview of summarization techniques for large-scale graphs, which are very prevalent due to their intrinsic ability to represent many natural phenomena and encode relationships between entities.
Recent advances in computing resources have made possible collecting enormous amounts of data, such as social media interactions, web browsing, product and service purchases, autonomous vehicle routing, activities via smart home sensors and health / wellness sensors, and more. Since summarization helps humans find structure and meaning in data, the data mining community has taken a strong interest in the task and accordingly has proposed many methods for a variety of data types. This tutorial aims to provide a comprehensive overview of summarization techniques for large-scale graphs, which are very prevalent due to their intrinsic ability to represent many natural phenomena and encode relationships between entities.
Graph summarization, compression and pattern discovery are tightly coupled: describing a graph succinctly leads to the discovery of interesting patterns, as well as to the detection of deviations or outliers. The objective of this tutorial is to give a systematic overview of graph summarization methods for static and dynamic networks with main emphasis on the important concepts, intuition, and main objectives, describe successful real-world applications, and present the open research problems in the field. Connections to compression and pattern/outlier discovery will be drawn throughout the tutorial.
This tutorial is based on our survey paper:
Yike Liu, Abhilash Dighe, Tara Safavi, Danai Koutra. A Graph Summarization: A Survey.
Prerequisites: Although we will provide a high-level introduction, some knowledge of linear algebra will be helpful. The emphasis will be on the intuition behind all the formal concepts, methods and tools. All the non-trivial concepts will be introduced and defined.
Overview
-
Part I. Summarization of Plain and Attributed Static Graphs [50 min + 10 min Q & A]
The first part will focus on models, methods and algorithms for summarizing a single graph (e.g., a snapshot or aggregate network). We will start with methods that use solely the structure of a graph. We will categorize the approaches based on their key methodological ideas (e.g., group-based vs. influence-based vs. pattern-based) and present representative algorithms. Moreover, we will provide a taxonomy of the methods based on their output (e.g., supergraph vs. sparsified graph vs. compressed graph) and main objective (e.g., storage, efficiency, visualization).
-
Introduction: Motivation and Challenges
Methods for graph structure summarization (group-based, simplification-based, compression-based, influence-based, pattern-based methods and distributed summarization)
Real-world applications
-
Methods for collective summarization of structure and side information (group-based, compression-based, influence-based, pattern-based)
Methods for dynamic graph summarization (pattern-based, influence-based,compression-based approaches)
Real-world applications
Oper research problems
Slides
[Download] The slides are available in ppsx form. Any comments or suggestions are welcome!For more details, check out our survey paper!
Yike Liu, Abhilash Dighe, Tara Safavi, Danai Koutra. A Graph Summarization: A Survey.
Presenter Bio
 Danai Koutra is an Assistant Professor in Computer Science and Engineering at University of Michigan, where she leads the Graph Exploration and Mining at Scale (GEMS) Lab. Her research focuses on methods for exploring large-scale graphs, including graph summarization, graph similarity, network alignment, and anomaly detection.
She won the 2016 ACM SIGKDD Dissertation award, and an honorable mention for the SCS Doctoral Dissertation Award (CMU). She holds one ``rate-1'' patent and has six (pending) patents on bipartite graph alignment; has multiple papers in top data mining conferences, including 2 award-winning papers; and her work has been covered by the popular press, such as the MIT Technology Review. She earned her Ph.D. and M.S. in Computer Science from CMU in 2015. She is serving as secretary of the SIAM Activity Group on Data Mining and Analytics, and has co-organized 2 tutorials on graph similarity and alignment.
Danai Koutra is an Assistant Professor in Computer Science and Engineering at University of Michigan, where she leads the Graph Exploration and Mining at Scale (GEMS) Lab. Her research focuses on methods for exploring large-scale graphs, including graph summarization, graph similarity, network alignment, and anomaly detection.
She won the 2016 ACM SIGKDD Dissertation award, and an honorable mention for the SCS Doctoral Dissertation Award (CMU). She holds one ``rate-1'' patent and has six (pending) patents on bipartite graph alignment; has multiple papers in top data mining conferences, including 2 award-winning papers; and her work has been covered by the popular press, such as the MIT Technology Review. She earned her Ph.D. and M.S. in Computer Science from CMU in 2015. She is serving as secretary of the SIAM Activity Group on Data Mining and Analytics, and has co-organized 2 tutorials on graph similarity and alignment.